
一、核心结论
先说结论
1.1 端到端是时代趋势
如果你在 2026 年还在纠结要不要深入研究 Apollo 和 Autoware,我的建议是:作为学习材料可以,作为生产框架要慎重。
原因很简单:端到端已经不是趋势,而是现实。从特斯拉的 FSD V12 到国内各家车企的端到端方案,行业已经完成了从「模块化」到「神经网络直出」的范式转移。而 Apollo 和 Autoware 的架构设计,本质上还是围绕传统的「感知-预测-规划-控制」模块化范式展开的。
1.2 传统方案的也还有学习价值
但这不意味着它们毫无价值。如果你的团队:
- 还在做传统的分模块方案(这在商用车、矿卡、园区物流等场景依然主流)
- 需要理解自动驾驶系统的「经典架构」和各模块的职责边界
- 想学习大型 C++ 工程的代码规范、模块解耦和 ROS 集成
那么 Apollo 和 Autoware 依然是优质的学习素材。尤其是它们的架构设计、传统算法实现(如 A_、Lattice Planner、Hybrid A_ 等)、传感器标定流程,这些都是工业级的参考案例。
但记住:模型相关的部分,还是需要自己搞定。开源框架里的感知模型、预测模型,基本都是 2018-2020 年左右的技术水平,与当前的 BEV Transformer、occupancy network、端到端规划模型相比,已经落后一个代际。
1.3 新人友好
如果你是自动驾驶的初学者,Apollo 和 Autoware 的代码库是绝佳的「照猫画虎」对象:
- 清晰的模块划分和接口定义
- 完整的工程化实践(单元测试、CI/CD、文档体系)
- 大量注释和配置文件示例
这比直接去啃端到端黑盒模型的代码,学习曲线要友好得多。
二、两大开源框架的前世今生
2.1 Apollo:百度的「自动驾驶安卓」梦
Google或许就是百度眼中的自己吧~

背景
- 诞生时间:2017 年 4 月开源
- 主导方:百度
- 初衷:对标 Waymo,打造自动驾驶领域的「安卓系统」,通过开源生态降低行业门槛
- 技术栈:C++、ROS/Cyber RT、Protobuf、百度内部工具链
演进历程
- Apollo 1.0-3.0(2017-2018):快速迭代,从封闭场地到简单城市道路,主打「开箱即用」
- Apollo 5.0(2019):引入 Cyber RT 替代 ROS,性能优化,支持多传感器融合
- Apollo 6.0-7.0(2020-2021):开始向云端服务、仿真平台、车路协同方向延伸
- 2022 年至今:开源社区活跃度下降,百度重心转向 Apollo Go(Robotaxi 商业化)和萝卜快跑
架构特点
- 模块化设计极致,每个模块都有独立的配置文件和 DAG(有向无环图)定义
- 重度依赖 Protobuf 做消息传递
- Cyber RT 对实时性优化较好,但学习成本高于 ROS
- 文档和示例丰富,但版本迭代导致部分文档过时
2.2 Autoware:日本开源社区的「民主化」方案
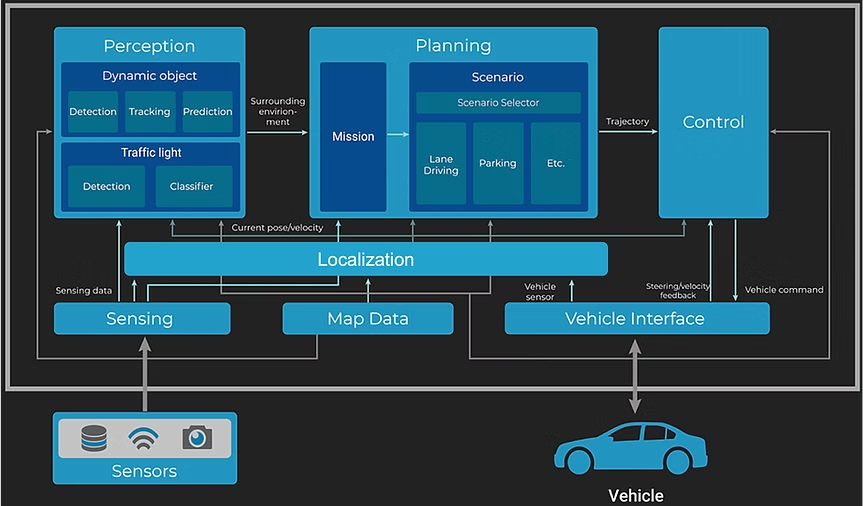
背景
- 诞生时间:2015 年由名古屋大学开源
- 主导方:Tier IV(2018 年成立,推动 Autoware.Auto 和 Autoware.Core)
- 初衷:让中小企业和研究机构也能参与自动驾驶研发
- 技术栈:C++、ROS/ROS2、标准开源库
演进历程
- Autoware.AI(2015-2020):基于 ROS1,功能全但代码质量参差不齐
- Autoware.Auto(2019-2022):从零重写,基于 ROS2,强调代码质量和安全认证(ISO 26262)
- Autoware.Core(2022-至今):合并 AI 和 Auto,统一架构,简化部署
架构特点
- 完全基于 ROS2,与开源生态无缝集成
- 代码风格更接近「学术范」,可读性强
- 模块间耦合度低,方便替换和实验
- 文档偏向「假设你懂 ROS」,新手门槛稍高
2.3 异同点对比
| 维度 | Apollo | Autoware |
|---|---|---|
| 架构哲学 | 百度内部工程实践外溢,强调性能和商业化 | 社区驱动,强调灵活性和标准化 |
| 通信框架 | Cyber RT(自研) | ROS2(开源标准) |
| 代码质量 | 工业级,但部分模块过度设计 | 学术与工业的平衡,重构后质量提升 |
| 学习曲线 | 陡峭(需理解 Cyber RT 和 DAG) | 中等(假设熟悉 ROS) |
| 仿真工具 | DreamView + Apollo Studio(闭源云服务) | 集成 Carla、LGSVL 等开源仿真器 |
| 商业化案例 | 百度 Robotaxi、部分主机厂合作 | Tier IV 的 Robotaxi、日本公交/物流项目 |
| 社区活跃度 | 2022 年后明显下降 | 持续活跃,尤其 ROS2 生态推动 |
| 硬件适配 | 针对特定传感器优化(如禾赛、Velodyne) | 通用性更强,但需自行调优 |
Apollo 更像大厂的开源公关,核心技术和工程能力藏在闭源部分(个人觉得如果认真搞开源,也不至于如此)。Autoware 更接近真正的社区项目,但商业化能力不如前者。
三、学习资源推荐
如果你决定深入学习这两个框架,以下是我建议的高质量内容源:
- 知乎专栏搜索 Apollo / Autoware (早期的知乎还是有很多高质量内容)
- Apollo / Autoware 官方文档,两者的文档写的虽然都不算详细,但是基本都覆盖到了
虽然推荐的只有两个途径,但相信我,看精不看杂,就别去CSDN等地方吃百家饭了
通用学习建议
- 先跑通再读代码:两个框架都提供 Docker 镜像和 demo 数据,先把系统跑起来,理解数据流
- 从配置文件入手:YAML/Protobuf 配置文件是理解模块参数的快捷方式
- 画架构图:用 draw.io 或白板,梳理模块间的消息订阅关系
- 不要陷入细节:初期目标是「理解架构」,而非「搞懂每一行代码」
四、企业里的真实使用场景
4.1 主机厂和 Tier 1 怎么用?
根据我接触的几家公司的实践,大致分三类:
1. 直接 fork 改造(少数)
- 典型案例:某些商用车/矿卡公司会 fork Apollo,替换感知模型,保留规划控制
- 原因:这些场景对实时性和泛化能力要求低,传统方案够用
- 问题:后续升级困难,基本变成「自己的代码库」
2. 参考架构自研(主流)
- 典型案例:造车新势力、头部主机厂
- 做法:学习 Apollo/Autoware 的模块划分和接口设计,但核心算法全部自研
- 重点借鉴:
- 传感器标定流程
- 仿真测试框架
- 日志和回放系统
- ROS/Cyber RT 的通信模式
3. 完全自研 + 端到端(前沿)
- 典型案例:特斯拉、华为、理想、小鹏的端到端团队
- Apollo/Autoware 的角色:新人培训材料,或者作为「降级方案」的备胎
- 核心技术栈:自研训练框架、BEV Transformer、Occupancy Network、端到端 Planner
4.2 开源框架的「隐性价值」
即使不直接使用,Apollo 和 Autoware 依然在以下方面发挥作用:
- 招聘筛选:要求候选人「熟悉 Apollo 架构」是快速判断其系统工程能力的方式
- 技术预研:新算法上车前,先在 Autoware 上验证可行性
- 对外演示:给投资人/客户展示时,Apollo 的 DreamView 界面比自研界面更「专业」
五、端到端时代,该看什么?
5.1 为什么端到端是必然?
三个核心原因:
- 信息损失:传统方案每个模块都要做信息压缩(3D bbox → 轨迹预测 → 路径规划),误差累积严重
- 长尾问题:规则和启发式算法难以覆盖 corner case,而神经网络可以从数据中学习
- 工程效率:端到端减少了模块间的接口调试成本,迭代速度更快
当然,端到端也有问题(可解释性差、数据需求量大、安全认证困难),但趋势已经无法逆转。
5.2 新的学习方向
要理解端到端时代该学什么,得先搞清楚这条技术路线是怎么一步步演化过来的。
传统方案的问题在于,感知模块输出的是 3D 检测框(bbox),这种离散的物体表达丢失了大量空间信息。你检测到了前车、行人、路沿,但车道间的可行驶区域、不规则障碍物、地面的坑洼,这些都没法用 bbox 表达。于是就有了 BEV(鸟瞰图)表征。
BEV 的核心思路是把多个相机的视角统一投影到俯视平面上,形成一张类似「上帝视角」的特征图。BEVFormer、BEVDet 这些工作解决的就是如何高效地做这个投影,以及怎么用 Transformer 来融合时序信息。学 BEV 的重点不是背论文,而是理解空间表征的统一化——从多视角的 2D 图像,怎么重建出 3D 空间的结构。
但 BEV 还不够细。它给你一张特征图,但具体哪些位置能走、哪些不能走,还需要后续模块去解析。所以下一步是 Occupancy Network(占用网络)。
Occupancy 把空间切成体素(voxel),每个体素标注是「occupied」还是「free」,甚至可以区分是车、人还是静态障碍物。特斯拉在 2022 年 AI Day 展示的 Occupancy Network 就是这个思路。相比 bbox,Occupancy 能表达任意形状的物体和可行驶区域,这对处理异形障碍物(路障、锥桶、施工区)至关重要。Tesla’s Occupancy Network、SurroundOcc 这些论文值得细读,重点看体素化表征怎么设计、稀疏卷积怎么加速、多传感器(camera+lidar)怎么融合。
有了 Occupancy,下一步自然就是端到端规划。既然神经网络已经能输出精细的空间占用,为什么还要把它转成中间表示再交给传统规划器?直接让网络输出轨迹或者控制指令不就行了?
UniAD 是第一批真正意义上的端到端方案,它把感知、预测、规划全部放进一个网络,损失函数直接优化最终的轨迹。VAD、SparseDrive 在此基础上进一步压缩中间表示。特斯拉的 FSD V12 更激进,直接从像素到控制指令,中间没有任何可解释的模块。这个阶段要学的是如何设计端到端的损失函数、如何保证安全性(imitation learning vs reinforcement learning)、如何处理分布外数据。
但端到端还不是终点。现在的端到端方案本质上是「反应式」的——看到当前场景,输出当前动作。而人类司机开车会「预判」:前面路口可能有人闯红灯、旁边车道的车可能要并线。这就引出了 VLA(Vision-Language-Action)和世界模型。
VLA 的思路是引入语言作为中间表征,让模型先「理解」场景(比如输出「前方路口,左侧有行人等待过马路」),再基于理解做决策。理想的 VLM-Planner 就是这个方向。而世界模型更进一步,它不仅理解当前场景,还能预测未来。给定当前状态和可能的动作,世界模型生成未来几秒的视频或特征,规划器基于预测结果选择最优动作。
Wayve 的 GAIA-1、Drive-WM、英伟达的 Cosmos 都在做这个。技术上主要依赖 Video Diffusion 和生成式模型。这条路线的终极目标是 AGI——模型不仅能开车,还能理解物理世界的因果关系,做出类人的长期规划。
所以整个演进路径是:
BBox(离散物体) → BEV(统一表征) → Occupancy(精细空间) → 端到端规划(感知规划一体) → VLA/世界模型(预测未来、长期规划)
每一步都在解决上一步的瓶颈。学的时候别跳步,BEV 没搞懂就去看世界模型,基本看不明白。老老实实从 BEVFormer 开始,把代码跑通,理解 Transformer 怎么做空间变换,再往后走。
5.3 传统方案还能学到什么?
即使在端到端时代,以下传统技能依然有价值:
- 传感器标定:无论什么方案,Camera-Lidar 外参标定都是基础
- 坐标系转换:车体坐标系、世界坐标系、像素坐标系的转换逻辑
- 控制理论:PID、MPC、LQR 等,端到端也需要控制模块兜底
- 系统工程:日志、仿真、回放、OTA,这些工程能力框架无关
六、总结与建议
给不同人群的建议
如果你是在校学生
- 可以深入学习 Apollo/Autoware,作为理解自动驾驶「全貌」的途径
- 重点学架构设计、代码规范、传统算法
- 不要指望开源框架里的感知/预测模型能直接用于科研
如果你是算法工程师
- 快速过一遍架构,理解模块间的接口
- 重点看感知和预测模块的数据流,但模型部分跳过
- 把时间投入到 BEV、Occupancy、端到端论文的复现上
如果你是系统工程师
- Apollo 的 Cyber RT 和 Autoware 的 ROS2 值得深入研究
- 学习它们的日志系统、仿真框架、CI/CD 流程
- 参考它们的配置管理和模块解耦思路
如果你在创业公司
- 慎重直接使用,除非是低速园区场景
- 可以参考架构,但核心算法必须自研
- 考虑直接上端到端方案,长期看更有竞争力
最后说几句
Apollo 和 Autoware 不是「过时的技术」,而是时代的产物。它们的价值在于:
- 降低了自动驾驶的认知门槛
- 为行业培养了第一批工程师
- 为新方案提供了「对照组」
但如果你的目标是做出最先进的自动驾驶系统,开源框架只是起点,端到端才是方向。