
0. 前言
📚 本文是一篇关于 nuScenes 数据集的深度技术解析,内容涵盖 15 个章节,建议收藏后慢慢阅读。
nuScenes 是目前学术界和工业界最广泛使用的自动驾驶感知 Benchmark,几乎所有 BEV 感知、3D 检测、Occupancy 方向的论文都以它为评测基准。然而,网上关于 nuScenes 的资料大多停留在「怎么下载」「怎么跑通 demo」的层面,缺乏对数据集本身的系统性梳理。
本文将从工程实践视角,对 nuScenes 进行一次全面拆解:
| 章节 | 内容 | 适合谁看 |
|---|---|---|
| 1-5 | 数据集概览、传感器规格、标注体系、数据结构、评测指标 | 所有研究者 |
| 6-7 | nuScenes 成为主流的原因、与 Waymo / Argoverse 2 对比 | 选型决策者 |
| 8-9 | 官方扩展数据集、E2E 训练局限性与 nuPlan | 端到端研究者 |
| 10 | Occ3D / OpenOcc / SurroundOcc / OpenOccupancy 四大 Occupancy 数据集深度对比 | Occupancy 研究者 |
| 11-12 | nuscenes-devkit 可视化详解、经典工作汇总 | 工程落地者 |
| 13-14 | 训练 Tricks(CBGS、GT-Aug、Multi-sweep 等)、使用建议 | “炼丹师” |
无论你是自动驾驶的新人还是老人,这篇文章都值得一读
1. 数据集概览
1.1 基本规模
| 指标 | 数值 |
|---|---|
| 场景数量 | 1,000 scenes(每个 20s) |
| 相机图像 | 约 140 万张 |
| LiDAR sweeps | 约 39 万帧 |
| RADAR sweeps | 约 140 万帧 |
| 关键帧数量 | 4 万帧(2Hz 标注频率) |
| 3D Bounding Boxes | 约 140 万个 |
| LiDAR 语义标注点数 | 11 亿点(Panoptic nuScenes 扩展) |
1.2 采集地点
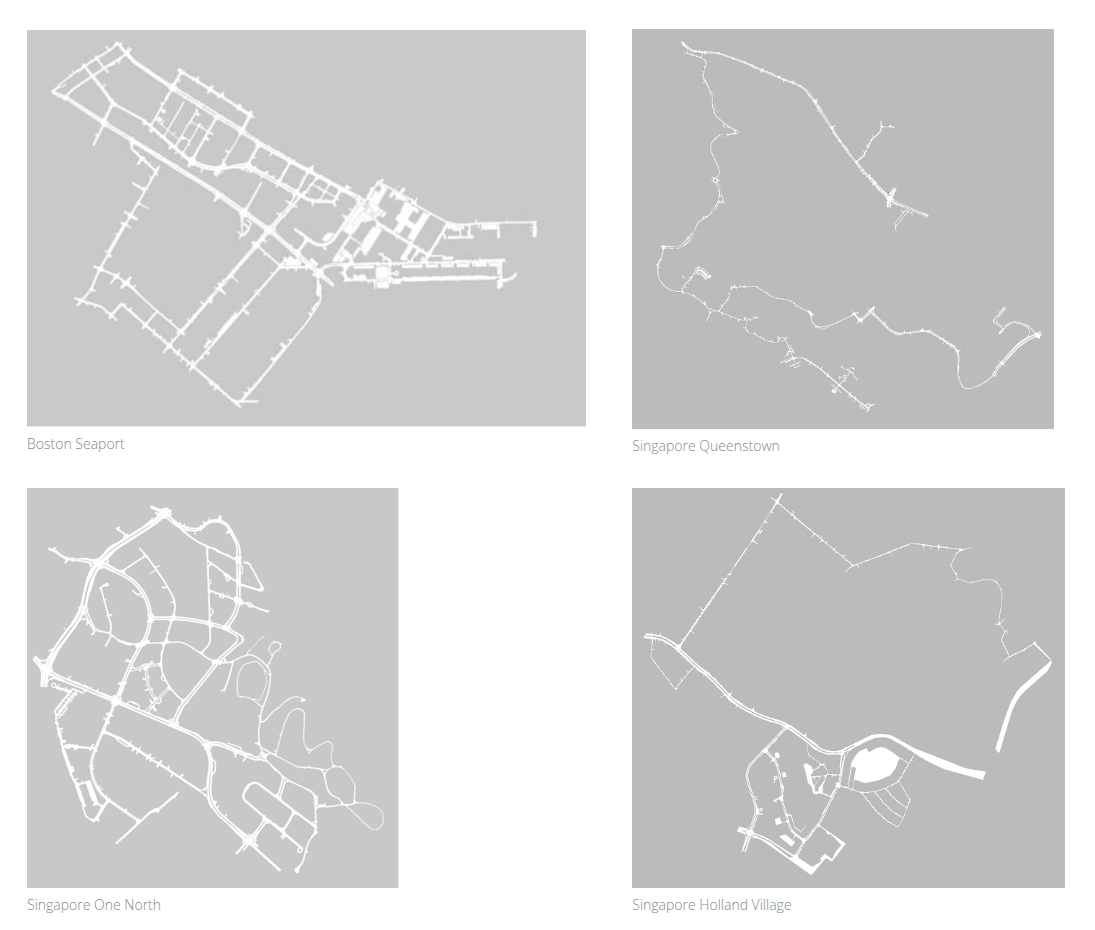
- 波士顿(美国):右侧行驶,主要采集区域为 Boston Seaport
- 新加坡:左侧行驶,主要采集区域为 One North、Queenstown、Holland Village
两地的交通规则差异为算法的泛化能力提供了良好的测试场景
2. 传感器配置
nuScenes 是首个提供完整 360° 传感器套件的大规模数据集:
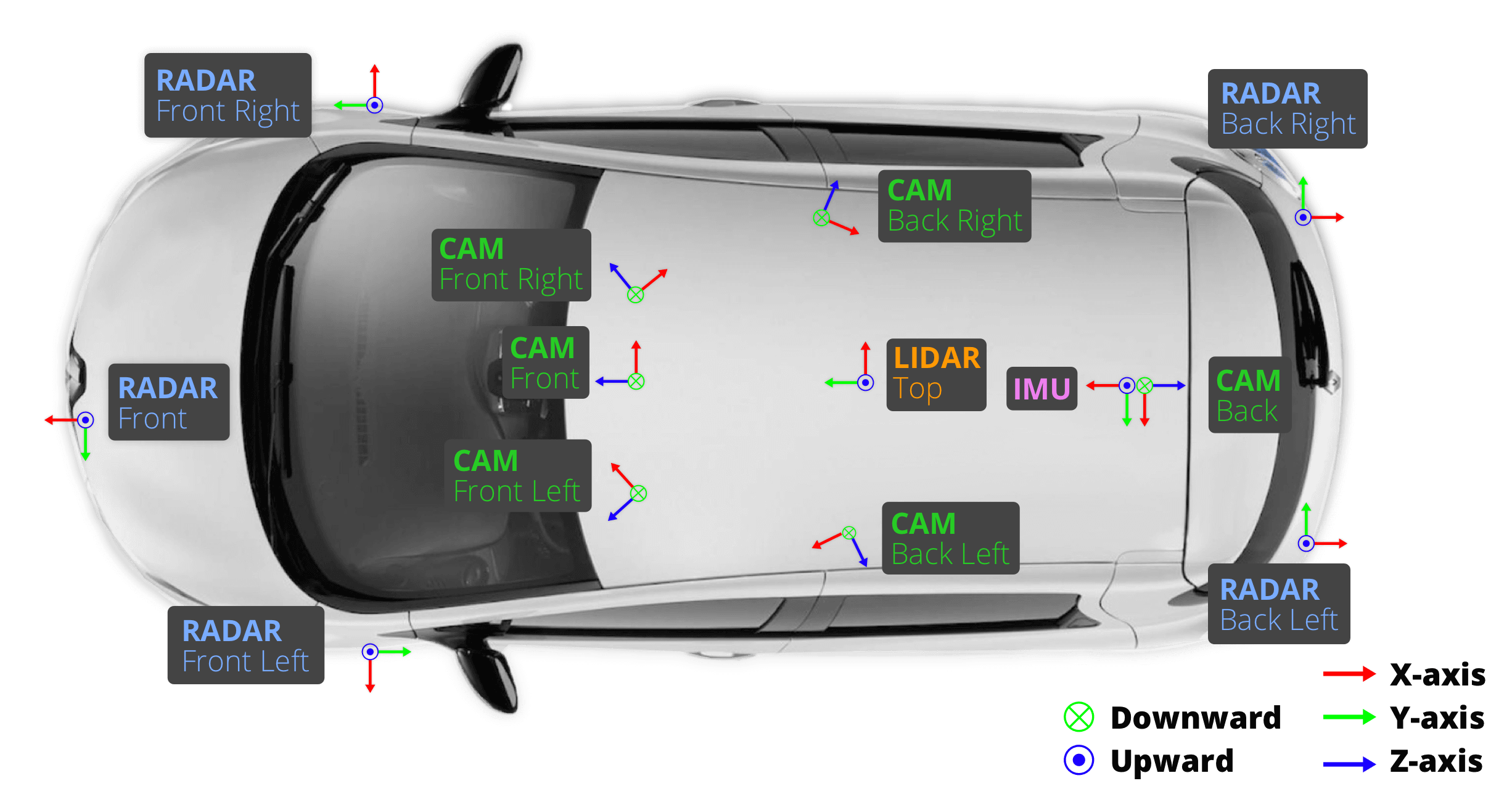
2.1 传感器列表
| 传感器类型 | 数量 | 覆盖范围 |
|---|---|---|
| Camera | 6 | 360° 环视 |
| LiDAR | 1 | 360°(Velodyne HDL-32E) |
| RADAR | 5 | 360° |
| GPS | 1 | - |
| IMU | 1 | - |
2.2 LiDAR 详细规格
型号:Velodyne HDL-32E
| 参数 | 规格 | |
|---|---|---|
| 线束数 | 32 beams | |
| 采集频率 | 20 Hz | |
| 水平 FOV | 360° | |
| 垂直 FOV | +10° 至 -30°(41.33°) | |
| 每圈点数 | ~1080 点 | |
| 点云速率 | 约 139 万点/秒(双回波模式) | |
| 有效距离 | 70m(最大 100m) | |
| 精度 | ± 2 cm | |
| 激光波长 | 905 nm(Class 1 人眼安全) |
与 KITTI 对比:KITTI 使用 Velodyne HDL-64E(64 线),nuScenes 的 32 线点云更稀疏,但成本更低,更接近量产车配置。
2.3 相机详细规格
型号:Basler acA1600-60gc + Evetar Lens N118B05518W
| 参数 | 规格 |
|---|---|
| 传感器 | 1/1.8” CMOS |
| 原始分辨率 | 1600 × 1200 |
| 实际输出 | 1600 × 900(ROI 裁剪) |
| 采集频率 | 12 Hz |
| 镜头焦距 | 5.5 mm,F1.8 |
| 曝光时间 | 自动曝光,最大 20 ms |
| 图像格式 | Bayer8 → BGR → JPEG 压缩 |
2.4 相机 FOV 与布局
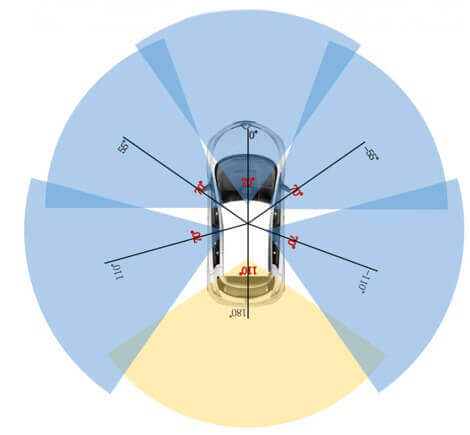
| 相机 | FOV | 方向 |
|---|---|---|
| CAM_FRONT | 70° | 正前方 |
| CAM_FRONT_LEFT | 70° | 前左 55° |
| CAM_FRONT_RIGHT | 70° | 前右 55° |
| CAM_BACK | 110° | 正后方 |
| CAM_BACK_LEFT | 70° | 后左 |
| CAM_BACK_RIGHT | 70° | 后右 |
前向和侧向相机之间偏移 55°,确保相邻相机视野有重叠,实现完整 360° 覆盖。后视相机 FOV 更大(110°)以弥补后方视野要求。
2.5 传感器同步机制
nuScenes 采用精确的时间同步策略:
- 相机曝光时刻与 LiDAR 顶部扫描线对齐
- 当 LiDAR 扫描到相机视野中心时触发相机曝光
- LiDAR 运行在 20Hz,相机运行在 12Hz,12 次相机曝光均匀分布在 20 次 LiDAR 扫描中
- 确保多模态数据的严格时间对齐
3. 标注体系
3.1 目标检测类别(10 类)
nuScenes 原始标注 23 类,检测挑战合并为 10 类:
| 类别 | 描述 |
|---|---|
| car | 轿车 |
| truck | 卡车 |
| bus | 公交车 |
| trailer | 拖车 |
| construction_vehicle | 工程车 |
| pedestrian | 行人 |
| motorcycle | 摩托车 |
| bicycle | 自行车 |
| traffic_cone | 交通锥 |
| barrier | 护栏 |
3.2 目标属性标注
除了 3D Bounding Box,还标注了丰富的属性:
- 可见性(visibility):0-100% 四档
- 活动状态(activity):如行人的站立/行走/坐下
- 姿态(pose):如车辆的停止/移动
3.3 语义分割类别(32 类)
Panoptic nuScenes 扩展提供点云语义标注,包含:
- 前景目标:车辆、行人、骑行者等
- 背景结构:道路、人行道、建筑、植被等
- 动静态区分:可移动物体 vs 静态结构
4. 数据组织结构
4.1 文件目录结构
nuScenes 数据集下载后的推荐组织方式(兼容 mmdetection3d):
nuscenes/
├── maps/ # 高精地图(4 张栅格化地图)
│ ├── basemap/ # 底图
│ ├── expansion/ # 扩展图层
│ ├── prediction/ # 预测用地图
│ ├── 36092f0b03a857c6a3403e25b4b7aab3.png # boston-seaport
│ ├── 37819e65e09e5547b8a3ceaefba56bb2.png # singapore-onenorth
│ ├── 53992ee3023e5494b90c316c183be829.png # singapore-hollandvillage
│ └── 93406b464a165eaba6d9de76ca09f5da.png # singapore-queenstown
│
├── samples/ # 关键帧数据(2Hz,带标注)
│ ├── CAM_FRONT/ # 前向相机图像
│ │ ├── n015-2018-07-18-11-07-57+0800__CAM_FRONT__1531883530412470.jpg
│ │ └── ...
│ ├── CAM_FRONT_LEFT/ # 前左相机图像
│ ├── CAM_FRONT_RIGHT/ # 前右相机图像
│ ├── CAM_BACK/ # 后向相机图像
│ ├── CAM_BACK_LEFT/ # 后左相机图像
│ ├── CAM_BACK_RIGHT/ # 后右相机图像
│ ├── LIDAR_TOP/ # 顶部 LiDAR 点云(.pcd.bin)
│ ├── RADAR_FRONT/ # 前向毫米波雷达
│ ├── RADAR_FRONT_LEFT/ # 前左毫米波雷达
│ ├── RADAR_FRONT_RIGHT/ # 前右毫米波雷达
│ ├── RADAR_BACK_LEFT/ # 后左毫米波雷达
│ └── RADAR_BACK_RIGHT/ # 后右毫米波雷达
│
├── sweeps/ # 非关键帧数据(原始频率,无标注)
│ ├── CAM_FRONT/ # 同 samples,12Hz
│ ├── CAM_FRONT_LEFT/
│ ├── ...
│ ├── LIDAR_TOP/ # 20Hz 点云
│ └── RADAR_*/ # 13Hz 雷达数据
│
├── lidarseg/ # 点云语义分割标签(可选)
│ └── v1.0-{mini,trainval,test}/
│ ├── {sample_data_token}_lidarseg.bin # 逐点类别标签
│ └── ...
│
├── v1.0-mini/ # Mini 子集元数据(10 scenes)
├── v1.0-trainval/ # 训练+验证集元数据(850 scenes)
└── v1.0-test/ # 测试集元数据(150 scenes,无标注)
├── attribute.json # 目标属性定义
├── calibrated_sensor.json # 传感器标定(内外参)
├── category.json # 类别定义(23 类)
├── ego_pose.json # 车辆位姿(全局坐标)
├── instance.json # 目标实例(跨帧 tracking ID)
├── log.json # 采集日志(车辆、日期、地点)
├── map.json # 地图引用
├── sample.json # 关键帧定义(2Hz)
├── sample_annotation.json # 3D Box 标注
├── sample_data.json # 传感器数据索引
├── scene.json # 场景定义(20s 连续段)
├── sensor.json # 传感器定义
└── visibility.json # 可见性定义4.2 核心概念关系
scene (场景)
└── sample (关键帧, 2Hz)
├── sample_data (传感器数据指针)
│ ├── CAM_FRONT → samples/CAM_FRONT/xxx.jpg
│ ├── LIDAR_TOP → samples/LIDAR_TOP/xxx.pcd.bin
│ └── ...
└── sample_annotation (3D Box 标注)
├── instance_token → 跨帧目标 ID
├── category_token → 类别
├── attribute_tokens → 属性(可见性、姿态等)
└── translation, size, rotation → 3D 位姿4.3 关键帧 vs 非关键帧
| 类型 | 目录 | 频率 | 标注 | 用途 |
|---|---|---|---|---|
| 关键帧 | samples/ | 2 Hz | ✅ 有 3D Box | 训练 & 评测 |
| 非关键帧 | sweeps/ | 原始频率 | ❌ 无 | 时序建模、点云累积 |
4.4 元数据 JSON 文件说明
| 文件 | 内容 | 主要字段 |
|---|---|---|
scene.json | 场景定义 | token, name, first/last_sample_token |
sample.json | 关键帧 | token, timestamp, scene_token, data |
sample_data.json | 传感器数据 | token, filename, ego_pose_token, calibrated_sensor_token |
sample_annotation.json | 3D 标注 | token, instance_token, translation, size, rotation |
instance.json | 目标实例 | token, category_token, first/last_annotation_token |
calibrated_sensor.json | 标定参数 | camera_intrinsic, translation, rotation |
ego_pose.json | 车辆位姿 | translation, rotation, timestamp |
4.5 数据划分
| 子集 | 元数据目录 | 场景数 | 用途 |
|---|---|---|---|
| mini | v1.0-mini/ | 10 | 代码调试、快速验证 |
| train | v1.0-trainval/ | 700 | 训练 |
| val | v1.0-trainval/ | 150 | 验证 |
| test | v1.0-test/ | 150 | 测试(标注不公开) |
5. 评测指标
5.1 3D 目标检测指标
NDS(nuScenes Detection Score) 是综合评价指标:
$$ NDS = \frac{1}{10}[5 \times mAP + \sum_{i=1}^{5}(1 - \min(1, TP_i))] $$
其中 $TP_i$ 包含 5 个 True Positive 指标:
| 指标 | 描述 |
|---|---|
| ATE | Average Translation Error(平移误差) |
| ASE | Average Scale Error(尺度误差) |
| AOE | Average Orientation Error(朝向误差) |
| AVE | Average Velocity Error(速度误差) |
| AAE | Average Attribute Error(属性误差) |
| 指标 | 描述 |
|---|---|
| ATE | Average Translation Error(平移误差) |
| ASE | Average Scale Error(尺度误差) |
| AOE | Average Orientation Error(朝向误差) |
| AVE | Average Velocity Error(速度误差) |
| AAE | Average Attribute Error(属性误差) |
mAP 计算特点:
- 使用 BEV 中心点距离而非 IoU 匹配
- 阈值:{0.5, 1, 2, 4} 米
- 对不同类别使用不同距离阈值
5.2 跟踪指标
- AMOTA:Average Multi-Object Tracking Accuracy
- AMOTP:Average Multi-Object Tracking Precision
- 沿用 CLEAR MOT 指标体系
5.3 预测指标
- minADE:最小平均位移误差
- minFDE:最小最终位移误差
- Miss Rate:预测轨迹偏离 GT 的比例
6. 为何 nuScenes 成为主流 Benchmark
nuScenes 在自动驾驶感知领域的主导地位并非偶然,而是多重因素的综合结果:
6.1 传感器配置最接近量产车
nuScenes 是首个提供完整 360° 环视传感器套件的公开数据集。6 个相机的配置与特斯拉、蔚来、理想等量产车高度一致。相比之下,KITTI 只有前向双目相机,研究成果难以迁移到实际产品。
6.2 数据规模与标注质量的平衡
- 1000 个场景、140 万 3D Box 标注量适中
- 完整数据约 300GB,学术实验室可承受
- 相比 Waymo(1200 万 Box、几 TB 数据),入门门槛更低
- 相比 KITTI(8 万 Box),统计意义更强
6.3 评测体系设计合理
NDS 指标综合考虑了 mAP + 5 个 TP 误差(位置、尺度、朝向、速度、属性),比 KITTI 单纯用 IoU 阈值更全面,能更好区分算法的实际性能差异。
6.4 开发工具完善
nuscenes-devkit 提供开箱即用的数据加载、可视化、评测脚本,降低了研究者的工程负担。
6.5 先发优势与网络效应
2019 年发布后被 BEVDet、BEVFormer 等开创性工作采用,形成了事实标准。新论文为了与前人对比,只能沿用同一 Benchmark。
6.6 场景多样性
波士顿(右舶)+ 新加坡(左舶)的组合提供了交通规则差异,有利于评估算法泛化能力。
7. 与其他高质量数据集对比
7.1 主流数据集概览
| 数据集 | 场景数 | 相机 | LiDAR | 3D Box 标注 | 地域 |
|---|---|---|---|---|---|
| nuScenes | 1,000 | 6(360°) | 1 | 140 万 | 波士顿、新加坡 |
| KITTI | 22 | 2(前向) | 1 | 8 万 | 德国 |
| Waymo | 1,150 | 5 | 5 | 1200 万 | 美国多城市 |
| Argoverse 2 | 1,000 | 7(360°) | 2 | - | 美国多城市 |
nuScenes 优势:
- 首个完整 360° 传感器套件
- 包含 RADAR 数据
- 左右舵行驶场景
- 丰富的属性标注
- 完善的开发工具包
7.2 Waymo Open Dataset
发布方:Waymo(Google 旗下自动驾驶公司)
发布时间:2019 年
| 指标 | 规格 |
|---|---|
| 场景数 | 1,150(每个 20s) |
| 相机 | 5 个(1 前 + 2 前侧 + 2 侧) |
| LiDAR | 5 个(1 顶部 64 线 + 4 短距) |
| 3D Box 标注 | 约 1200 万 |
| 标注频率 | 10 Hz |
| 采集地域 | 美国多城市(旧金山、凤凰城等) |
优势:
- 标注规模最大(1200 万 3D Box)
- LiDAR 点云密度高(64 线顶部 + 4 个短距)
- 标注频率 10Hz(nuScenes 仅 2Hz)
- 提供 2D/3D 联合标注
局限:
- 数据体积巨大(几 TB),对存储和算力要求高
- 许可证限制较严格(需注册、禁止商用)
- 仅美国场景,缺乏国际多样性
7.3 Argoverse 2
发布方:Argo AI(福特 & 大众投资,2022 年已解散)
发布时间:2021 年
| 指标 | 规格 |
|---|---|
| 场景数 | 1,000(传感器数据集) |
| 相机 | 7 个环视 + 2 个立体前视 |
| LiDAR | 2 个 32 线 |
| 高精地图 | 6 个城市,覆盖 2,000+ km |
| 标注频率 | 10 Hz |
| 采集地域 | 美国 6 城市 |
核心特色:
- 高精地图质量最高:提供车道级拓扑、交通标志、人行横道等丰富地图元素
- 包含三个子数据集:Sensor(传感器)、Lidar(纯点云)、Motion Forecasting(轨迹预测)
- Motion Forecasting 子集包含 25 万个场景、超 500 万轨迹,是预测任务的首选
适用场景:
- 在线高精地图构建(MapTR、MapTRv2 均在 AV2 评测)
- 轨迹预测研究
- 多模态 BEV 感知
7.4 数据集选择建议
| 研究方向 | 推荐数据集 | 理由 |
|---|---|---|
| BEV 感知入门 | nuScenes | 社区成熟、复现方便 |
| 追求 SOTA | Waymo | 数据量大、标注精度高 |
| 在线建图 | Argoverse 2 | HD Map 标注最完善 |
| 轨迹预测 | Argoverse 2 | Motion Forecasting 子集专为预测设计 |
| 端到端规划 | nuPlan | 唯一大规模 Planning 数据集 |
8. nuScenes 官方扩展数据集
8.1 nuScenes-lidarseg
- 11 亿点云逐点语义标注
- 32 个语义类别
- 支持点云分割任务
8.2 Panoptic nuScenes
- 在 lidarseg 基础上增加实例分割
- 支持全景分割任务
8.3 nuImages
- 9.3 万张带 2D 标注的图像
- 用于 2D 检测研究
9. nuScenes 在端到端训练中的局限性
nuScenes 虽然是感知 Benchmark 的事实标准,但在端到端自动驾驶(E2E) 研究中存在明显不足:
9.1 核心局限
| 维度 | 局限性 | 影响 |
|---|---|---|
| 数据量 | 仅 5.5 小时有效驾驶数据 | 难以学习复杂驾驶策略 |
| 场景数 | 1000 个场景,每个仅 20s | 长尾场景覆盖不足 |
| 规划标注 | 无 Planning 标注(仅有 ego pose) | 只能用 ego 轨迹作为伪标签 |
| 评测方式 | 仅支持开环评测 | 无法评估闭环决策能力 |
| 交互场景 | 缺乏复杂交互标注 | 难以评估博弈行为 |
9.2 nuPlan:面向规划的数据集
为弥补上述不足,Motional 于 2021 年发布了 nuPlan——首个大规模自动驾驶规划数据集:
| 指标 | nuScenes | nuPlan |
|---|---|---|
| 数据量 | 5.5 小时 | 1500+ 小时 |
| 场景数 | 1,000 | 120 万+ |
| 标注类型 | 感知标注 | 感知 + 规划轨迹 |
| 评测方式 | 开环 | 开环 + 闭环仿真 |
| 采集地域 | 2 城市 | 4 城市(波士顿、匹兹堡、新加坡、拉斯维加斯) |
nuPlan 特色:
- 提供专家驾驶轨迹作为 Planning GT
- 内置闭环仿真器,支持 reactive agents
- 定义了 Planning Challenge 评测协议
9.3 nuPlan 的局限性
尽管 nuPlan 在数据规模上有巨大提升,但仍存在根本性问题:
- 仿真保真度不足
- 其他交通参与者采用简单的 replay 或规则驱动
- 无法模拟真实的人类驾驶反应
- 仿真与真实世界存在 sim-to-real gap
- 场景多样性有限
- 仍以常规驾驶为主
- 高风险 corner case(如紧急避让、复杂路口博弈)覆盖不足
- 传感器数据缺失
- nuPlan 主要提供向量化数据(检测结果、地图)
- 原始传感器数据(图像、点云)需额外下载,体积巨大
9.4 闭环仿真:依然是开放难题
端到端自动驾驶的评测核心在于闭环仿真——让模型的决策影响环境,环境再反馈给模型。目前的主要挑战:
⚠️ 核心矛盾:高保真仿真需要精确建模人类行为,但人类行为本身难以预测。
有前景的闭环仿真方案:
| 方案 | 代表工作 | 核心思路 | 局限 |
|---|---|---|---|
| 数据驱动仿真 | TrafficSim、BITS | 从真实数据学习交通参与者行为模型 | 泛化到未见场景困难 |
| 生成式仿真 | GAIA-1、DriveDreamer、MagicDrive | 用 Diffusion/World Model 生成逼真驾驶视频 | 物理一致性难以保证 |
| 神经渲染仿真 | UniSim、MARS、StreetGaussians | 用 NeRF/3DGS 重建真实场景,支持视角合成 | 动态物体建模困难 |
| 混合仿真 | Waymax、DriveArena | 结合数据驱动 + 规则 + 可控生成 | 工程复杂度高 |
当前研究趋势:
- World Model(世界模型)成为热点:通过视频预测学习环境动态,如 GAIA-1、DriveDreamer-2
- 可控生成:在保持真实性的同时,允许编辑场景(如插入行人、改变天气)
- Sim-to-Real:在仿真中训练,迁移到真实世界的能力评估
💡 小结:nuScenes 适合感知研究,nuPlan 是 Planning 研究的起点,但真正的闭环端到端评测仍需依赖下一代仿真技术。
10. 基于 nuScenes 的 3D Occupancy 数据集深度对比
随着 Tesla 提出 Occupancy Network 概念,3D 占据感知成为自动驾驶感知的热门方向。由于 nuScenes 官方未提供 Occupancy 标注,学术界陆续构建了多个基于 nuScenes 的 Occupancy 数据集。
10.1 主流 Occupancy 数据集概览
| 数据集 | 发布时间 | 会议 | 类别数 | Flow 标注 | 分辨率 |
|---|---|---|---|---|---|
| Occ3D-nuScenes | 2023 | NeurIPS | 16 | ❌ | 0.4m |
| OpenOcc | 2023 | ICCV | 16 | ✅ | 0.5m |
| SurroundOcc | 2023 | ICCV | 16 | ❌ | 0.5m |
| OpenOccupancy | 2023 | ICCV | 16 | ❌ | 0.2m |
10.2 标注生成流程对比
所有 Occupancy 数据集的核心挑战是:如何从稀疏的 LiDAR 点云生成稠密的体素标注?
各数据集采用了相似但有差异的自动标注流水线:
通用流程(三步走)
1. LiDAR 点云累积 (Point Cloud Accumulation)
└─ 聚合多帧 LiDAR 扫描,增加点云密度
2. 遮挡推理 (Occlusion Reasoning / Ray Casting)
└─ 判断每个体素是「占据」「空闲」还是「不可见」
3. 场景补全 (Scene Completion / Refinement)
└─ 填补点云稀疏区域的语义标注各数据集差异
| 步骤 | Occ3D-nuScenes | OpenOcc | SurroundOcc | OpenOccupancy |
|---|---|---|---|---|
| 点云累积 | 多帧聚合 + Poisson 重建 | 多帧聚合 | 多帧聚合 + NeRF 隐式重建 | 多帧聚合 + 多传感器融合 |
| 遮挡推理 | 基于可见性的 Ray Casting | Ray Casting | Ray Casting + 图像引导 | 动态物体单独处理 |
| 场景补全 | 图像引导的体素细化 | 语义先验补全 | 多尺度特征融合 | LiDAR-Camera 交叉验证 |
10.3 Occ3D-nuScenes 详解
来源:清华 MARS Lab
标注流程:
- 点云稠密化:累积前后多帧 LiDAR 点云,使用 Poisson 表面重建生成连续 Mesh
- 语义迁移:将 nuScenes 3D Box 标注和 Panoptic nuScenes 语义标注迁移到体素
- 可见性建模:通过 Ray Casting 判断每个体素对各相机的可见性
- 体素细化:利用图像特征修正边界区域的语义类别
特点:
- 提供 Waymo 和 nuScenes 两个版本
- 引入「可见性」概念区分「空闲」和「不可见」
- 被学术界广泛采用作为标准 Benchmark
体素范围:
X: [-40m, 40m] → 200 格
Y: [-40m, 40m] → 200 格
Z: [-1m, 5.4m] → 16 格
分辨率: 0.4m10.4 OpenOcc 详解
来源:OpenDriveLab(与 OccNet / Scene as Occupancy 论文配套)
核心差异:
- 提供 Flow 标注:为 8 类前景物体(车、人、骑行者等)标注了运动流向量
- 支持 4D 感知:可用于 Motion Prediction 和 Planning 任务
标注流程:
- 多帧点云对齐(动静态分离处理)
- 基于 nuScenes 3D Box 的实例关联
- 计算相邻帧之间的物体位移作为 Flow GT
体素范围:
X: [-50m, 50m] → 200 格
Y: [-50m, 50m] → 200 格
Z: [-5m, 3m] → 16 格
分辨率: 0.5m适用场景:端到端自动驾驶研究(如 UniAD、VAD 使用 OpenOcc 评测 Planning)
10.5 SurroundOcc 详解
来源:清华大学
核心创新:引入 NeRF 隐式重建 辅助标注生成
标注流程:
- 训练场景级 NeRF 模型重建连续 3D 场景
- 从 NeRF 中采样得到稠密的占据信息
- 结合 LiDAR 点云和图像语义进行标签融合
特点:
- 理论上可生成任意分辨率的标注
- NeRF 重建质量影响最终标注精度
- 对动态物体处理相对较弱
10.6 OpenOccupancy 详解
来源:上海交通大学
核心差异:
- 最高分辨率:0.2m(其他数据集为 0.4-0.5m)
- 多传感器融合标注:同时利用 LiDAR 和 Camera 进行交叉验证
标注流程:
- 累积前后 10 帧 LiDAR 点云
- 动态物体使用 3D Box 跟踪结果独立对齐
- 静态场景使用位姿变换累积
- 图像语义分割结果用于验证和补全边界
体素范围:
X: [-51.2m, 51.2m] → 512 格
Y: [-51.2m, 51.2m] → 512 格
Z: [-5m, 3m] → 40 格
分辨率: 0.2m10.7 关键差异总结
| 对比维度 | Occ3D-nuScenes | OpenOcc | SurroundOcc | OpenOccupancy |
|---|---|---|---|---|
| 分辨率 | 0.4m(中等) | 0.5m(较粗) | 0.5m(较粗) | 0.2m(最细) |
| Flow 标注 | ❌ | ✅(8 类前景) | ❌ | ❌ |
| 标注方法 | Poisson 重建 | 多帧累积 | NeRF 隐式重建 | 多传感器融合 |
| 动态物体处理 | 基于 Box 跟踪 | 独立对齐 | 较弱 | 独立对齐(最完善) |
| 学术影响力 | 最广泛使用 | E2E 研究首选 | 中等 | 高精度研究 |
| 适用任务 | 3D SSC | 3D SSC + Planning | 3D SSC | 高精度 SSC |
10.8 Occupancy 数据集格式与使用指南
各数据集虽然标注流程不同,但最终提供的数据格式大致相似,核心是 3D 体素网格 + 语义标签。
通用数据格式
occ_data/
├── gts/ # Ground Truth 标签
│ ├── {scene_name}/
│ │ ├── {sample_token}.npz # 体素标签文件
│ │ └── ...
│ └── ...
└── infos/ # 元数据索引
├── occ_infos_train.pkl
└── occ_infos_val.pkl单帧标签文件结构(.npz)
import numpy as np
# 加载标签文件
data = np.load('xxx.npz')
# 核心字段
voxel_label = data['semantics'] # shape: (X, Y, Z), dtype: uint8
# - 值 0~15: 语义类别 ID
# - 值 255: 忽略/不可见区域
mask_lidar = data['mask_lidar'] # shape: (X, Y, Z), dtype: bool
# - True: LiDAR 可见区域
# - False: 遮挡/超出范围
mask_camera = data['mask_camera'] # shape: (X, Y, Z), dtype: bool
# - True: 至少一个相机可见
# - False: 相机不可见
# OpenOcc 额外提供
flow = data['flow'] # shape: (X, Y, Z, 3), dtype: float16
# - 前景体素的运动向量 (vx, vy, vz)各数据集具体格式差异
| 数据集 | 标签文件格式 | 体素尺寸 (X×Y×Z) | 额外字段 |
|---|---|---|---|
| Occ3D-nuScenes | .npz | 200×200×16 | mask_lidar, mask_camera |
| OpenOcc | .npz | 200×200×16 | flow (运动向量) |
| SurroundOcc | .npy | 200×200×16 | 无 |
| OpenOccupancy | .npz | 512×512×40 | mask_lidar, mask_camera |
语义类别映射(16 类)
OCC_CLASSES = [
'others', # 0: 其他/未知
'barrier', # 1: 护栏
'bicycle', # 2: 自行车
'bus', # 3: 公交车
'car', # 4: 轿车
'construction_vehicle', # 5: 工程车
'motorcycle', # 6: 摩托车
'pedestrian', # 7: 行人
'traffic_cone', # 8: 交通锥
'trailer', # 9: 拖车
'truck', # 10: 卡车
'driveable_surface', # 11: 可行驶区域
'other_flat', # 12: 其他平面
'sidewalk', # 13: 人行道
'terrain', # 14: 地形
'manmade', # 15: 人造结构
'vegetation', # 16: 植被
]
IGNORE_LABEL = 255坐标系与体素索引
以 Occ3D-nuScenes 为例:
# 体素空间定义
VOXEL_SIZE = [0.4, 0.4, 0.4] # 单位: 米
POINT_CLOUD_RANGE = [-40, -40, -1, 40, 40, 5.4] # [x_min, y_min, z_min, x_max, y_max, z_max]
# 从世界坐标 (x, y, z) 转换到体素索引 (i, j, k)
def world_to_voxel(x, y, z):
i = int((x - POINT_CLOUD_RANGE[0]) / VOXEL_SIZE[0])
j = int((y - POINT_CLOUD_RANGE[1]) / VOXEL_SIZE[1])
k = int((z - POINT_CLOUD_RANGE[2]) / VOXEL_SIZE[2])
return i, j, k
# 从体素索引转换回世界坐标(体素中心)
def voxel_to_world(i, j, k):
x = POINT_CLOUD_RANGE[0] + (i + 0.5) * VOXEL_SIZE[0]
y = POINT_CLOUD_RANGE[1] + (j + 0.5) * VOXEL_SIZE[1]
z = POINT_CLOUD_RANGE[2] + (k + 0.5) * VOXEL_SIZE[2]
return x, y, z数据加载示例
Occ3D-nuScenes 加载:
import numpy as np
import pickle
# 加载元数据
with open('data/occ3d/occ_infos_train.pkl', 'rb') as f:
infos = pickle.load(f)
# 遍历样本
for info in infos:
sample_token = info['token']
scene_name = info['scene_name']
# 加载 Occupancy GT
occ_path = f'data/occ3d/gts/{scene_name}/{sample_token}.npz'
occ_data = np.load(occ_path)
semantics = occ_data['semantics'] # (200, 200, 16)
mask_lidar = occ_data['mask_lidar'] # (200, 200, 16)
mask_camera = occ_data['mask_camera'] # (200, 200, 16)
# 仅评估相机可见区域
valid_mask = mask_camera
valid_semantics = semantics[valid_mask]OpenOcc 加载(含 Flow):
import numpy as np
# 加载标签
occ_data = np.load('data/openocc/gts/scene-0001/xxx.npz')
semantics = occ_data['semantics'] # (200, 200, 16)
flow = occ_data['flow'] # (200, 200, 16, 3)
# 获取前景物体的运动向量
foreground_mask = (semantics >= 1) & (semantics <= 10) # 前景类别
foreground_flow = flow[foreground_mask] # (N, 3)与 nuScenes 原始数据对齐
from nuscenes.nuscenes import NuScenes
import numpy as np
nusc = NuScenes(version='v1.0-trainval', dataroot='data/nuscenes')
# 获取 sample
sample = nusc.get('sample', sample_token)
# 获取 LiDAR 点云
lidar_data = nusc.get('sample_data', sample['data']['LIDAR_TOP'])
lidar_path = nusc.dataroot + '/' + lidar_data['filename']
points = np.fromfile(lidar_path, dtype=np.float32).reshape(-1, 5)
# 获取 ego pose(用于坐标变换)
ego_pose = nusc.get('ego_pose', lidar_data['ego_pose_token'])
# 获取相机图像
for cam_name in ['CAM_FRONT', 'CAM_FRONT_LEFT', 'CAM_FRONT_RIGHT',
'CAM_BACK', 'CAM_BACK_LEFT', 'CAM_BACK_RIGHT']:
cam_data = nusc.get('sample_data', sample['data'][cam_name])
cam_path = nusc.dataroot + '/' + cam_data['filename']
# 加载图像...目录组织建议(兼容 mmdet3d)
data/
├── nuscenes/ # nuScenes 原始数据
│ ├── maps/
│ ├── samples/
│ ├── sweeps/
│ ├── v1.0-trainval/
│ └── v1.0-test/
│
├── occ3d-nuscenes/ # Occ3D 标注
│ ├── gts/
│ │ ├── scene-0001/
│ │ │ ├── {sample_token}.npz
│ │ │ └── ...
│ │ └── ...
│ └── occ3d_infos_{train,val}.pkl
│
└── openocc/ # OpenOcc 标注
├── gts/
└── openocc_infos_{train,val}.pkl常见代码库支持
| 数据集 | 官方 Repo | mmdet3d 支持 | ||
|---|---|---|---|---|
| Occ3D | Tsinghua-MARS-Lab/Occ3D | ✅ 官方提供 config | ||
| OpenOcc | OpenDriveLab/OpenScene | ✅ UniAD/VAD 兼容 | ||
| SurroundOcc | weiyithu/SurroundOcc | ✅ BEVFormer 风格 | ||
| OpenOccupancy | JeffWang987/OpenOccupancy | ✅ 独立框架 |
10.9 选择建议
| 研究目标 | 推荐数据集 | 理由 |
|---|---|---|
| 入门 / Benchmark 复现 | Occ3D-nuScenes | 使用最广泛,论文对比方便 |
| 端到端自动驾驶 | OpenOcc | 提供 Flow 标注,支持 Planning 评测 |
| 高精度占据感知 | OpenOccupancy | 0.2m 分辨率,细节更丰富 |
| 隐式重建研究 | SurroundOcc | NeRF-based 标注方法可参考 |
10.10 Occupancy 评测指标
mIoU(mean Intersection over Union) 是标准评测指标:
$$ mIoU = \frac{1}{C} \sum_{c=1}^{C} \frac{TP_c}{TP_c + FP_c + FN_c} $$
其中 $C$ 为类别数(通常 16 类)。
IoU(Scene Completion IoU):仅评估「占据 vs 空闲」的二分类准确率,不考虑语义类别。
10.11 Occupancy 数据集的局限性
- 标注噪声:自动标注流程不可避免引入噪声,尤其是远距离和遮挡区域
- 动态物体边界:高速运动物体的边界模糊
- 语义歧义:部分类别(如 vegetation vs terrain)边界定义模糊
- 分辨率限制:0.2-0.5m 分辨率对小物体(行人、锥桶)表达能力有限
11. 开发工具与可视化
11.1 nuscenes-devkit 概览
官方 Python SDK,提供完整的数据加载、可视化、评测工具链:
pip install nuscenes-devkit核心功能模块:
| 模块 | 功能 | 典型用途 |
|---|---|---|
nuscenes.nuscenes | 数据加载与查询 | 获取 scene/sample/annotation |
nuscenes.utils | 坐标变换、数据类 | LiDAR→Camera 投影 |
nuscenes.eval | 评测脚本 | 计算 NDS/mAP |
nuscenes.map_expansion | 高精地图 API | 车道线、人行横道查询 |
nuscenes.prediction | 轨迹预测工具 | Agent 历史轨迹提取 |
| 模块 | 功能 | 典型用途 |
|---|---|---|
nuscenes.nuscenes | 数据加载与查询 | 获取 scene/sample/annotation |
nuscenes.utils | 坐标变换、数据类 | LiDAR→Camera 投影 |
nuscenes.eval | 评测脚本 | 计算 NDS/mAP |
nuscenes.map_expansion | 高精地图 API | 车道线、人行横道查询 |
nuscenes.prediction | 轨迹预测工具 | Agent 历史轨迹提取 |
11.2 常用 API
from nuscenes.nuscenes import NuScenes
# 初始化
nusc = NuScenes(version='v1.0-trainval', dataroot='/data/nuscenes')
# 获取场景
scene = nusc.scene[0]
# 获取 sample
sample = nusc.get('sample', scene['first_sample_token'])
# 获取传感器数据
cam_data = nusc.get('sample_data', sample['data']['CAM_FRONT'])
# 可视化
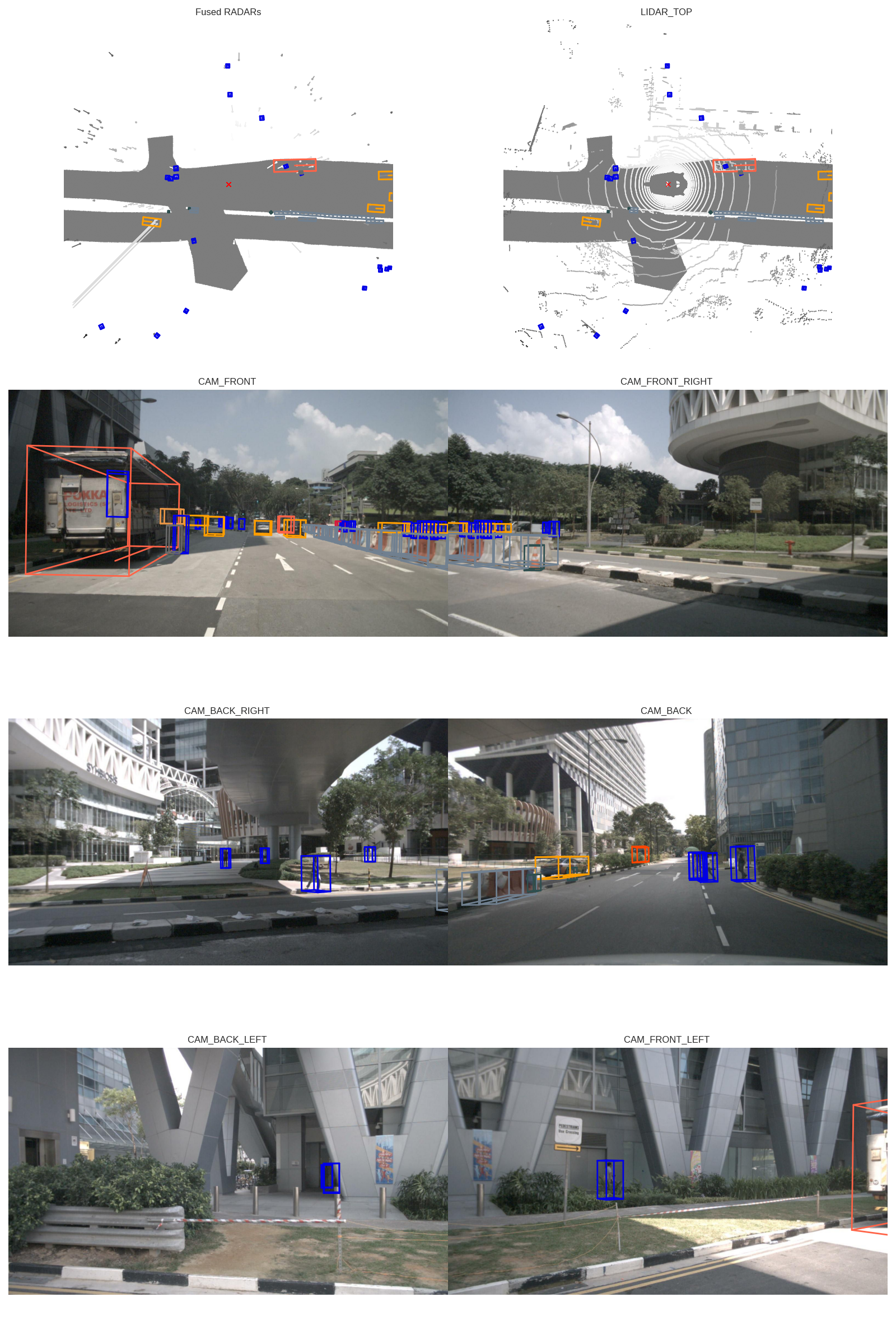
nusc.render_sample(sample['token'])11.3 可视化能力详解
nuscenes-devkit 提供了丰富的可视化功能,覆盖从单帧渲染到完整场景视频的各种需求:
单帧多模态渲染
# 渲染单个 sample 的所有传感器数据(6 相机 + LiDAR BEV + 3D Box)
nusc.render_sample(sample['token'])单传感器渲染
# 渲染单个相机图像 + 3D Box 投影
nusc.render_sample_data(sample['data']['CAM_FRONT'], with_anns=True)
# 渲染 LiDAR 点云(BEV 视角)
nusc.render_sample_data(sample['data']['LIDAR_TOP'], with_anns=True)点云累积可视化
# 累积多帧点云,获得更稠密的 BEV 图
nusc.render_sample_data(
sample['data']['LIDAR_TOP'],
nsweeps=10, # 累积 10 帧
underlay_map=True # 叠加地图底图
)特定标注渲染
# 渲染单个 3D Box 标注
ann_token = sample['anns'][0]
nusc.render_annotation(ann_token)场景视频渲染
# 渲染整个场景的视频(所有相机通道)
nusc.render_scene(scene['token'])
# 渲染单个通道的视频
nusc.render_scene_channel(scene['token'], 'CAM_FRONT')语义分割可视化(Lidarseg/Panoptic)
from nuscenes.nuscenes import NuScenes
# 初始化时加载 lidarseg 数据
nusc = NuScenes(version='v1.0-trainval', dataroot='/data/nuscenes', verbose=True)
# 渲染带语义标签的点云 BEV
nusc.render_sample_data(
sample['data']['LIDAR_TOP'],
show_lidarseg=True, # 显示语义标签
filter_lidarseg_labels=[10, 11] # 仅显示 truck 和 trailer 类别
)LiDAR 到相机投影
from nuscenes.utils.data_classes import LidarPointCloud
from nuscenes.utils.geometry_utils import view_points
# 加载点云
lidar_data = nusc.get('sample_data', sample['data']['LIDAR_TOP'])
pc = LidarPointCloud.from_file(nusc.dataroot + lidar_data['filename'])
# 获取标定参数
cam_data = nusc.get('sample_data', sample['data']['CAM_FRONT'])
cs_record = nusc.get('calibrated_sensor', cam_data['calibrated_sensor_token'])
# 投影到图像平面
points_2d = view_points(pc.points[:3, :], np.array(cs_record['camera_intrinsic']), normalize=True)高精地图可视化
from nuscenes.map_expansion.map_api import NuScenesMap
# 加载地图
nusc_map = NuScenesMap(dataroot='/data/nuscenes', map_name='singapore-onenorth')
# 渲染地图图层
fig, ax = nusc_map.render_layers(['road_segment', 'lane', 'ped_crossing'], figsize=(10, 10))
# 在指定位置渲染周围地图
nusc_map.render_map_patch(
box_coords=(300, 1000, 500, 1200), # (x_min, y_min, x_max, y_max)
layer_names=['drivable_area', 'lane_divider', 'ped_crossing']
)
11.4 可视化函数速查表
| 函数 | 功能 | 输入 |
|---|---|---|
render_sample() | 渲染完整 sample(6 相机 + BEV) | sample_token |
render_sample_data() | 渲染单个传感器数据 | sample_data_token |
render_annotation() | 渲染单个 3D Box | annotation_token |
render_scene() | 渲染场景视频(所有相机) | scene_token |
render_scene_channel() | 渲染场景视频(单通道) | scene_token, channel |
render_ego_pose() | 渲染自车轨迹 | - |
render_instance() | 渲染目标实例的跟踪轨迹 | instance_token |
12. 基于 nuScenes 的经典工作
12.1 3D 目标检测
| 方法 | 模态 | NDS | mAP | 特点 |
|---|---|---|---|---|
| PointPillars | L | 45.3 | 30.5 | 快速 LiDAR 检测 |
| CenterPoint | L | 67.3 | 60.3 | Center-based |
| TransFusion | L+C | 71.7 | 68.9 | Transformer 融合 |
| BEVFusion | L+C | 72.9 | 70.2 | BEV 空间融合 |
12.2 纯视觉 BEV 感知
| 方法 | NDS | mAP | 特点 |
|---|---|---|---|
| DETR3D | 42.5 | 34.9 | 3D query |
| BEVDet | 48.0 | 39.4 | LSS 架构 |
| BEVFormer | 56.9 | 48.1 | Transformer |
| SparseBEV | 62.9 | 55.8 | 稀疏 query |
12.3 端到端自动驾驶
| 方法 | L2 Error | 特点 |
|---|---|---|
| UniAD | 0.48m | 统一架构 |
| VAD | 0.41m | 向量化表示 |
13. 常见训练 Tricks / Best Practice
基于 nuScenes 训练 3D 检测模型时,以下技巧被广泛验证有效,可带来显著的性能提升:
13.1 数据增强
多帧点云累积(Multi-sweep Fusion)
nuScenes 单帧点云仅约 3.4 万点(32 线),远低于 Waymo 的 64 线点云密度。累积多帧 sweeps 可有效增加点云密度:
# 常用配置:累积 10 帧(约 0.5 秒)
sweeps = 10 # 官方 baseline 推荐值
# mmdetection3d 配置示例
point_cloud_range = [-51.2, -51.2, -5.0, 51.2, 51.2, 3.0]
data = dict(
train=dict(
pipeline=[
dict(type='LoadPointsFromFile', ...),
dict(type='LoadPointsFromMultiSweeps', sweeps_num=10), # 累积 10 帧
...
]
)
)效果:累积 10 帧可使有效点数提升 5-8 倍,mAP 通常提升 3-5 个点。
GT-Aug(Ground Truth Augmentation)
从数据库中随机采样 GT Box 及其内部点云,粘贴到当前场景中:
# 生成 GT 数据库
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes
# 输出: nuscenes_dbinfos_train.pkl
# 配置示例
db_sampler = dict(
data_root='data/nuscenes/',
info_path='data/nuscenes/nuscenes_dbinfos_train.pkl',
rate=1.0,
prepare=dict(
filter_by_difficulty=[-1],
filter_by_min_points=dict(
car=5, truck=5, bus=5, trailer=5,
construction_vehicle=5, traffic_cone=5,
barrier=5, motorcycle=5, bicycle=5, pedestrian=5
)
),
classes=['car', 'truck', ...],
sample_groups=dict(
car=2, truck=3, bus=4, trailer=6,
construction_vehicle=7, traffic_cone=2,
barrier=2, motorcycle=6, bicycle=6, pedestrian=2
)
)常规增强
# 点云增强
dict(type='GlobalRotScaleTrans',
rot_range=[-0.3925, 0.3925], # ±22.5°
scale_ratio_range=[0.95, 1.05],
translation_std=[0.5, 0.5, 0.5]),
dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),13.2 类别平衡采样(CBGS)
nuScenes 类别分布极度不均衡:car 占 40%+,而 bicycle、motorcycle 不足 1%。CBGS 通过重采样平衡各类别梯度:
# CBGS 核心思想
# 1. 统计每个类别的实例数
# 2. 按类别数量对 sample 进行重采样,使各类别采样概率接近
# 3. 每个 epoch 相当于对稀有类别过采样
# mmdetection3d 配置
dataset = dict(
type='CBGSDataset', # 启用 CBGS
dataset=dict(
type='NuScenesDataset',
...
)
)效果:CBGS 对稀有类别(bicycle、motorcycle、construction_vehicle)提升显著,mAP 通常提升 2-4 个点。
13.3 类别分组多头(Multi-group Head)
将形状相近的类别分组,每组使用独立的检测头:
# 推荐分组(来自 CBGS 论文)
class_groups = [
['car'], # 主流类别单独一组
['truck', 'construction_vehicle'], # 大型车辆
['bus', 'trailer'], # 超大型车辆
['barrier'], # 静态障碍物
['motorcycle', 'bicycle'], # 两轮车
['pedestrian', 'traffic_cone'], # 小型目标
]13.4 优化器与学习率
# AdamW + One Cycle Policy(常用配置)
optimizer = dict(
type='AdamW',
lr=1e-4,
weight_decay=0.01
)
lr_config = dict(
policy='cyclic',
target_ratio=(10, 1e-4),
cyclic_times=1,
step_ratio_up=0.4
)
# 或使用 Cosine Annealing
lr_config = dict(
policy='CosineAnnealing',
warmup='linear',
warmup_iters=1000,
warmup_ratio=1.0 / 10,
min_lr_ratio=1e-5
)13.5 训练周期
# 常用配置
total_epochs = 20 # LiDAR-only
total_epochs = 24 # 多模态融合(需要更多 epoch 收敛)
# BEVDet 系列通常使用 24 epochs
# CenterPoint 使用 20 epochs13.6 Tricks 效果汇总
| Trick | mAP 提升 | NDS 提升 |
|---|---|---|
| Multi-sweep (10帧) | +3~5 | +2~4 |
| GT-Aug | +2~4 | +1~3 |
| CBGS | +2~4 | +1~2 |
| Multi-group Head | +1~2 | +1 |
| Fade Strategy | +0.5~1 | +0.5 |
| Test Time Aug | +1~2 | +1 |
13.7 推荐训练流程
1. 数据准备
└─ 生成 pkl 信息文件 + GT 数据库
2. Baseline 训练
└─ 10-sweep + GT-Aug + 基础增强
└─ AdamW + Cosine/OneCycle
└─ 20 epochs
3. 加入 CBGS
└─ 观察稀有类别指标变化
4. 超参调优
└─ 学习率、增强强度、sweep 数量
5. 最终提交
└─ TTA(Test Time Augmentation)
└─ Model Ensemble(如需冲榜)14. 使用建议
14.1 数据下载
官网下载地址:https://www.nuscenes.org/nuscenes#download
完整数据约 300GB,建议:
- 先下载 mini 集验证流程
- 使用 v1.0-trainval 进行训练
- test 集仅用于最终评测
14.2 常见数据预处理
# 生成数据库信息文件
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes
# 输出文件
# - nuscenes_infos_train.pkl
# - nuscenes_infos_val.pkl
# - nuscenes_dbinfos_train.pkl(用于数据增强)14.3 坐标系说明
- 全局坐标系:以采集起点为原点
- 车辆坐标系:右-前-上(x-y-z)
- 相机坐标系:右-下-前
- LiDAR 坐标系:右-前-上
15. 许可证
- 非商业用途:免费使用
- 商业用途:需联系 nuScenes@motional.com 获取商业许可
参考资料
- 官网:https://www.nuscenes.org/
- 论文:nuScenes: A Multimodal Dataset for Autonomous Driving(CVPR 2020)
- GitHub:https://github.com/nutonomy/nuscenes-devkit