
基于 MMDetection3D 复现 LidarMultiNet 多任务框架,共享稀疏卷积编码器同时做 3D 检测与点云分割。检测持平 baseline,但分割 mIoU 仅 7.7%。核心瓶颈:检测优化的编码器在下采样中丢失了分割所需的空间细节。
我在 MMDetection3D 上复现了 LidarMultiNet 的多任务思路——用一个共享的稀疏卷积编码器同时做 3D 检测和点云语义分割。代码开源在 GitHub。
结论先说:检测完全不受影响,但分割几乎不可用。核心瓶颈不是训练策略,而是检测优化的编码器在下采样过程中丢掉了分割需要的空间细节。这篇文章记录完整过程:架构设计、实验数据、踩坑和工程反思。
1. 为什么要做多任务
量产车的感知系统要跑多个模型:3D 检测、语义分割、车道线、Freespace……每个模型各自一套 backbone,算力开销成倍增长。在 Orin 上,算力就是钱。
多任务学习的诉求很直接:一个编码器,多个任务头,省算力。检测要物体级语义,分割要逐点精细特征,两者在低层特征上大量重叠,理论上可以共享。
但理论和实际之间隔着一条鸿沟。这个项目就是为了搞清楚这条鸿沟有多宽。
2. 架构设计
2.1 整体结构
先看原论文的网络架构图:
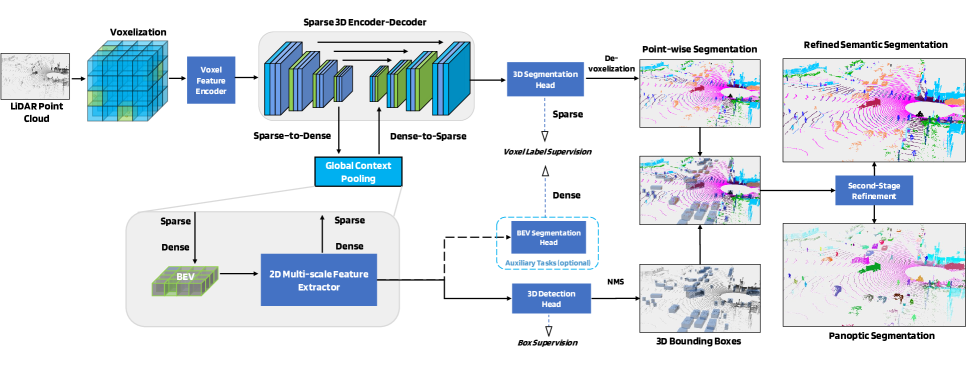
我的实现基于 CenterPoint 扩展。整体流程:点云经过体素化后进入共享的 SparseEncoderDecoder。编码器是 4 级稀疏卷积,通道数 16 → 32 → 64 → 128,每级 stride=2 下采样。解码器通过 SparseInverseConv3d 逐级上采样,配合 skip connection 恢复空间分辨率。
编码器输出的 BEV 特征送入 SECOND FPN → CenterHead,完成 3D 检测(10 类)。解码器输出的稀疏体素特征送入 SparseSegHead,完成逐点语义分割(17 类)。
和 U-Net 思路一致——编码器压缩空间提取语义,解码器恢复细节用于逐点预测。
2.2 核心模块
| 模块 | 作用 |
|---|---|
| CenterPointMultiTask | 多任务检测器,支持 freeze 控制检测/分割/编码器各分支 |
| SparseEncoderDecoder | 共享编码器-解码器,同时输出 BEV 特征和稀疏体素特征 |
| SparseSegDecoder | 独立分割解码器,用于冻结编码器场景 |
| SparseSegHead | 逐点分割头,Cross-Entropy + Lovász Loss |
2.3 Freeze 机制
模型提供三个独立的 freeze 开关:可以分别冻结检测分支、分割分支和共享编码器,外加分割 loss 权重控制。这让我能灵活切换训练策略——先联合训练,再冻结编码器单独训练分割解码器,观察不同策略下的效果差异。
3. 实验结果
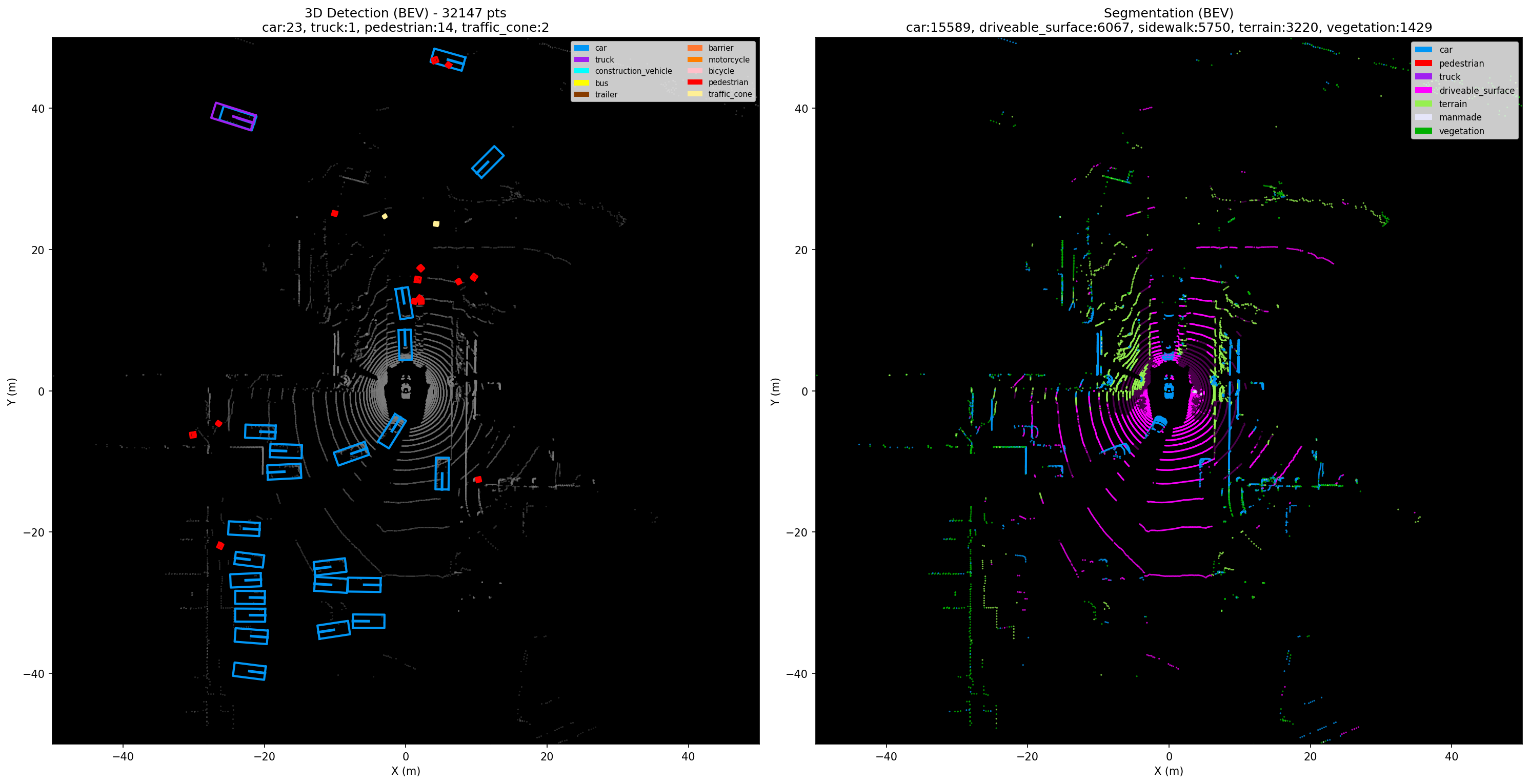
数据集用 nuScenes 全量训练集,4 张 RTX 4090 训练。每张图左侧是 BEV 视角的 3D 检测框,右侧是语义分割结果。
联合训练(1 epoch)可视化

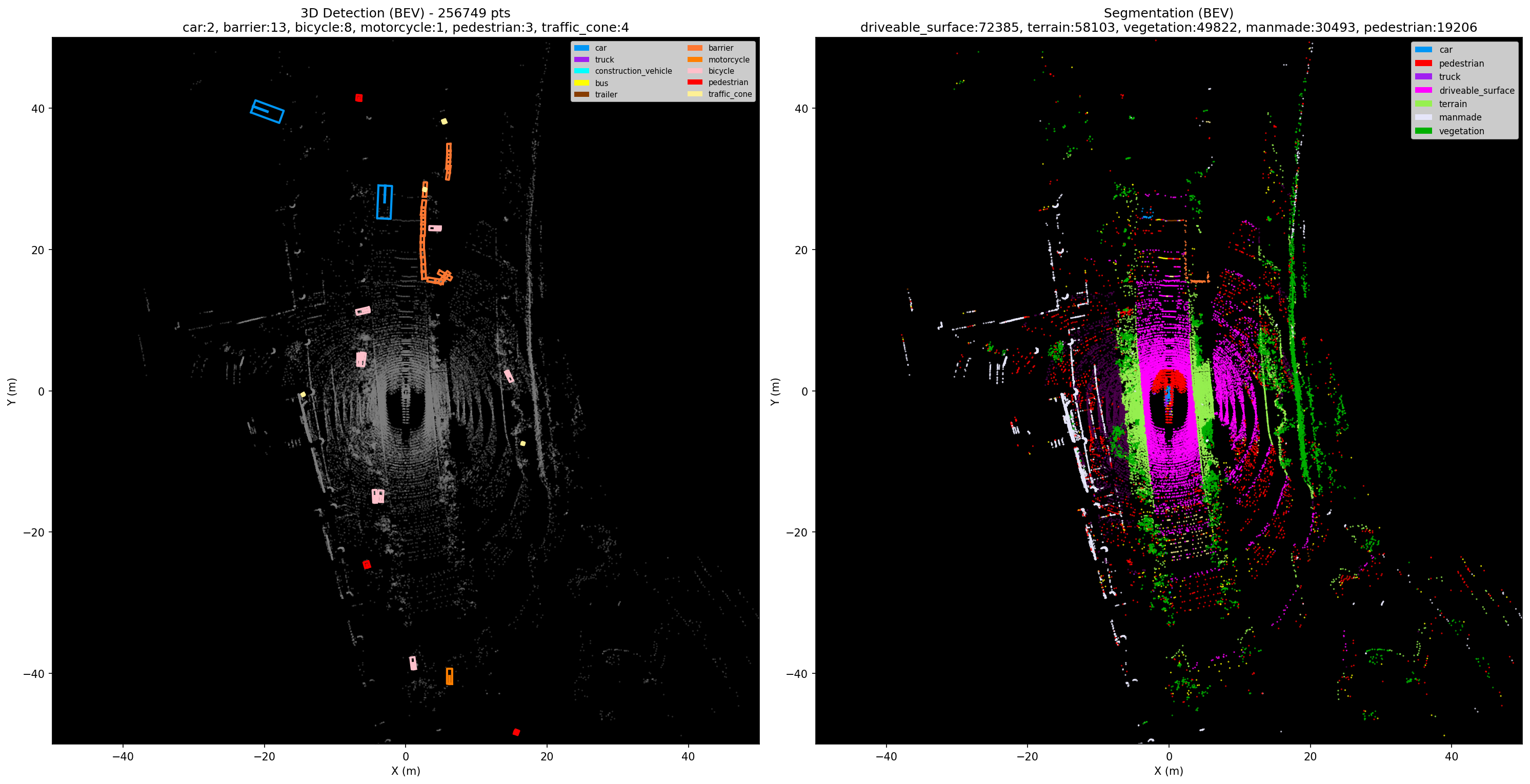
独立解码器(20 epochs)可视化
训练 20 epoch 后,大面积类别(可行驶区域、植被、建筑)的分割质量有明显提升:

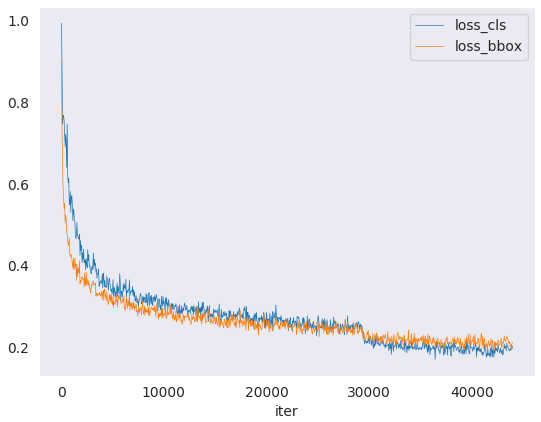
训练 Loss 曲线
3.1 实验一:联合训练(1 epoch)
| 任务 | 指标 | 数值 |
|---|---|---|
| Detection | mAP | 0.5835 |
| Detection | NDS | 0.6563 |
| Segmentation | mIoU | 0.0393 |
检测和 CenterPoint baseline 基本持平,多任务训练没有拖累检测性能。分割 mIoU 3.9%,几乎不可用。看到这个数字时我第一反应是代码写 bug 了,debug 了半天才确认——确实就是这么差。
1 个 epoch 对分割来说太少,17 类逐点分类的收敛速度远慢于检测。
3.2 实验二:独立解码器(20 epochs,冻结编码器)
冻结编码器和检测头,只训练分割解码器,20 个 epoch:
| 任务 | 指标 | 数值 |
|---|---|---|
| Detection | mAP | 0.5295 |
| Detection | NDS | 0.6253 |
| Segmentation | mIoU | 0.077 |
- Freeze 机制验证通过:检测指标跨 epoch 方差 < 0.1%,冻结确实生效
- 分割有提升但依然很差:mIoU 从 3.9% 到 7.7%,翻了一倍,离可用还差很远
- 大面积类别能学到,小物体完全学不到
3.3 逐类分割 IoU
按 IoU 排序,规律一目了然——前 6 名全是大面积背景类,后 5 名全是小物体,直接归零:
| 类别 | IoU | 类别 | IoU |
|---|---|---|---|
| driveable_surface | 0.234 | car | 0.055 |
| manmade | 0.174 | traffic_cone | 0.010 |
| terrain | 0.158 | bus | 0.009 |
| vegetation | 0.139 | pedestrian | 0.004 |
| barrier | 0.116 | construction_vehicle | 0.000 |
| sidewalk | 0.108 | motorcycle | 0.000 |
| truck | 0.097 | bicycle | 0.000 |
| trailer | 0.066 | ||
| other_flat | 0.064 |
原因很直接:检测优化的编码器做了 4 级 stride=2 下采样,空间分辨率缩小 16 倍,小物体的精细边界信息在编码过程中就被丢弃了。大面积类别靠粗粒度特征勉强能分辨,小物体没有任何机会。
4. 如果重来一次
这个项目最有价值的不是实验数字,而是几条工程认知。
检测编码器的特征不适合分割。 3D 检测编码器的目标是提取物体级语义——知道「这里有辆车」就够了,不需要精确到每个点。为此它做了激进的空间压缩。分割需要的恰恰相反:逐点的精细空间信息。解码器通过 SparseInverseConv3d 恢复分辨率,但已经丢失的细节补不回来。这不是「训练不够」的问题,是特征本身不包含分割需要的信息。
解码器容量已经触顶。 mIoU 在第 5 个 epoch 就到了 0.072,之后 15 个 epoch 只涨了 0.005。瓶颈不在解码器的学习能力,在输入特征的质量。
多任务架构本身是 work 的。 Freeze 控制、共享编码器、独立任务头,工程上都运行正确。问题出在特征质量,不在架构设计。
如果从头来过,我会这么做:
- 解冻编码器,用小学习率联合微调,让编码器同时适应两个任务
- 在编码器中间层加分割辅助监督,迫使每一级都保留空间信息
- 加深解码器,给更大的容量
- 对小物体做 Class-balanced sampling 或 Focal Loss
- 补全 TensorRT 推理链路,验证端到端部署性能
5. 部署笔记
训练出多任务模型不算难,部署到车端需要额外工程量,但在 NVIDIA 平台上没有想象中那么困难。
稀疏卷积部分(编码器 + 分割解码器),NVIDIA 官方已经通过 Lidar_AI_Solution 提供了完整的 TensorRT plugin,包括 SparseConvolution 和 SparseInverseConvolution。检测分支的 2D Conv 走标准 TensorRT 原生支持。
多任务相比单任务部署多出来的核心工程点是 Indices 共享:分割解码器的 SparseInverseConv3d 需要复用编码器前向传播时生成的卷积 indices。PyTorch 里 spconv 通过 indice_key 机制透明处理,部署时需要在 engine 段之间显式传递。不算特别难,但在 ONNX 导出和 C++ 推理代码中需要额外处理。
当前方案是把模型拆成 3 个 ONNX 段分别导出:SCN(稀疏编码器)、RPN(2D 检测)、SEG(稀疏解码器)。端到端推理验证还在进行中。
参考资料
- Ye et al.,「LidarMultiNet: Towards a Unified Multi-task Network for LiDAR Perception」(2022). arXiv:2209.09385
- Yin et al.,「Center-based 3D Object Detection and Tracking」(CVPR 2021)
- 项目代码:github.com/windzu/MMDet3D-LidarMultiNet