
前言
Hello,大家好。
这应该是我的第一篇正式的、系统性聊智驾的文章。说来惭愧,我虽然学生时期写过很多关于图像识别的博文,也开源过一些工程,但自从工作后就中断了写作和分享的习惯。偶尔开源一些有意思的工作,也没怎么分享过,更别说系统性地介绍自己的工作了。
但在前不久,我突然收到一封邮件。发件人是一位毕业了三四年的同学,他说非常感谢我之前写的一些博客和开源工程,帮助他当年顺利完成了毕设。我当时真的感慨颇深,没想到自己当年那么稚嫩的输出也可以帮到别人。
所以我开始想,或许我可以继续输出一些内容,或许真的可以帮到一些人。
在正式系统性输出之前,先简单介绍一下自己:
我从毕业至入行自动驾驶已经六年了。有过几段工作经历,待的都是一些比较小的智驾公司,一直从事感知相关的工作。目前在一家初创公司担任感知算法负责人。
因为视角有限,可能我的一些观点并不会有足够高的高度和深度,但只要能给阅读的你带来一点点帮助,我就满足了。
我想这个系列我会尽量避开枯燥的公式推导或代码讲解,而是从比较宏观的角度谈一些自己的观点。这样我写起来没什么压力,读者看起来也轻松。如果想要深入探讨细节,我之后或许会创建一个交流群,或者直接推荐一些我个人认为讲得很精细的文章。
好了,下面正式开始吧!
正文
入行六年,从最开始的野蛮快速增长——各家都在做可以跑一小段高速路的 Demo,到现如今已经比较成熟的「点到点」自动驾驶。
在这个过程中,我经历了太多的起伏:从资本热钱涌入、百花齐放,再到资本冷静、暗流涌动。工作内容和技术路线也是从一开始的「看不清方向、看不完论文」,到现如今的技术路线明确——伴随着无数公司被洗牌离场,同时也排除了很多错误答案。
不过今天不聊资本,就从一个资深从业者的角度,回顾一下这些年的技术发展,看看我们是如何一步步走向现在这个技术路线的,同时展望一下未来。
毕竟过完年我也算正式迈入 30 岁了,我也想理一理之后职业生涯的发展思绪。
首先,这些年智驾技术的发展给人最直观的感觉就是 ——「快」。
进步的速度快,技术的变革也很快。每当一个新的挑战出现,就会出现一个新的解决方向;而每当觉得「稳了」的时候,又会有新的需求和 Corner Case 被抛出,逼着我们推倒重来。
最近和几个刚毕业想要入行的学弟,以及很多应届求职者聊天,他们满口都是端到端、大模型、World Model。看着他们眼里的光,我突然想起了六年前的自己。
那时候我也以为,把感知、定位、规划、控制这几个模块拼好,车就能自己开了。而且这个结构多优雅呀,比学生时候玩的 RoboMaster 高级多了。我当时迫不及待地想要马上开干,验证自己的一些想法。
但是,从模块化的堆砌到现如今大行其道的端到端,这过程中到底发生了什么?又为什么会这样?下一步的技术路线又可能是什么?在这不断变化的过程中,有没有什么是「不变」的?
我觉得搞清楚这些,对于身处其中的工程师而言是有意义的。
在我看来,自动驾驶技术从「堆砌模块」走到「追求 AGI」,这不仅是技术的演进,更是一场工程师对自己认知的不断修正。下面是我的一些想法。
01. 分而治之:那个相信「拼图」的年代
如果要给自动驾驶的发展划分代际,我更愿意称最初的那几年为「泥瓦匠时代」。
回到 2016-2018 年左右,如果你问怎么实现自动驾驶,答案是极其标准的工程解法:
分而治之(Divide and Conquer),这就像传统算法中的分治算法一样优雅。
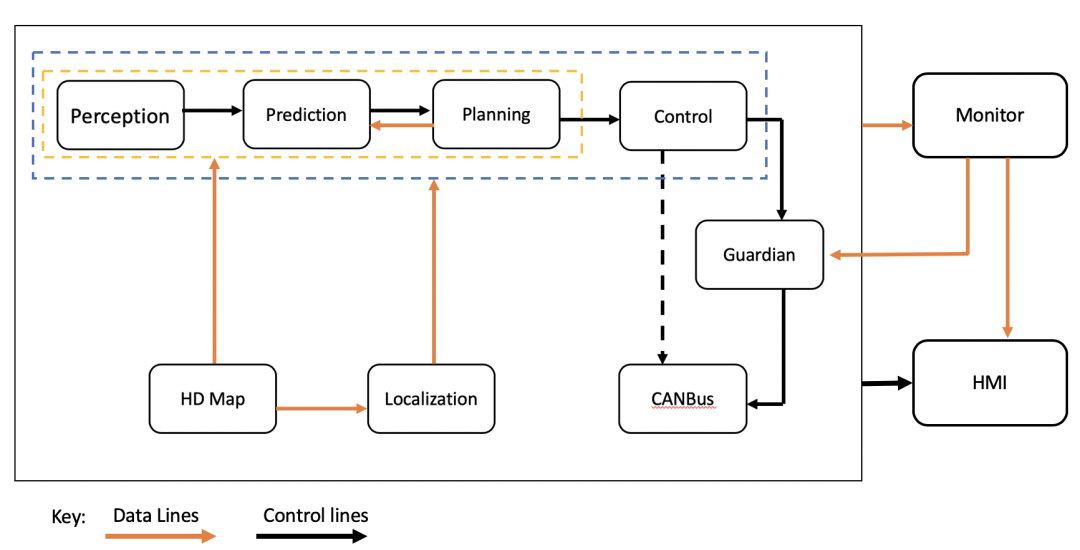
既然「开车」这件事太难,那就把它拆碎:
- 感知组:你们负责做眼睛,用深度学习或者传统算法检出障碍物,最好告诉我前面是人还是车;
- 定位组:你们负责搞清楚我在哪,精确到厘米;
- 规划组:你们拿着感知和定位的结果,再看看高精度地图,用数学算一条符合交规且不碰撞的轨迹,驾乘体验最好还得比较好;
- 控制组:你们负责把这条轨迹转化成油门和方向盘的指令。这是成熟算法了吧,应该好搞定。
现在回头看,这像极了一个拼凑出来的「弗兰肯斯坦」。但在当时,这就是最优解。
为什么?因为那时候的 AI 还不够强。它就像个刚学会认字的幼儿园小朋友,你不敢把性命攸关的方向盘完全交给它。我们只能用大量的「规则代码」(Rule-based),像保姆一样去兜底。
我记得很清楚,那时候为了处理一个「路口左转遇到对向遮挡」的场景,规划组的同事可能要写几百行 if-else:
“如果前车速度小于 x,且距离大于 y,且左侧无障碍物,则……”

这种工程思维在封闭园区或者高速公路上非常有效,也让最初所在的 Demo 公司老板赚了很多钱。但接着而来的是新的、更高的要求——当我们把车开进复杂的城市道路,噩梦开始了。
人类世界的复杂程度,是永远无法用 if-else 穷举完的。
我们试图用有限的规则,去定义无限的世界。这本身就是一种傲慢。
02. 特斯拉的「优雅」与规则的崩塌
转折点大概发生在特斯拉开始疯狂迭代 Autopilot 以及科技盛宴 AI Day,然后开始引入 BEV 的时候(至今还是很怀念那个时刻,也不知道什么时候 Tesla 会重启 AI Day)。
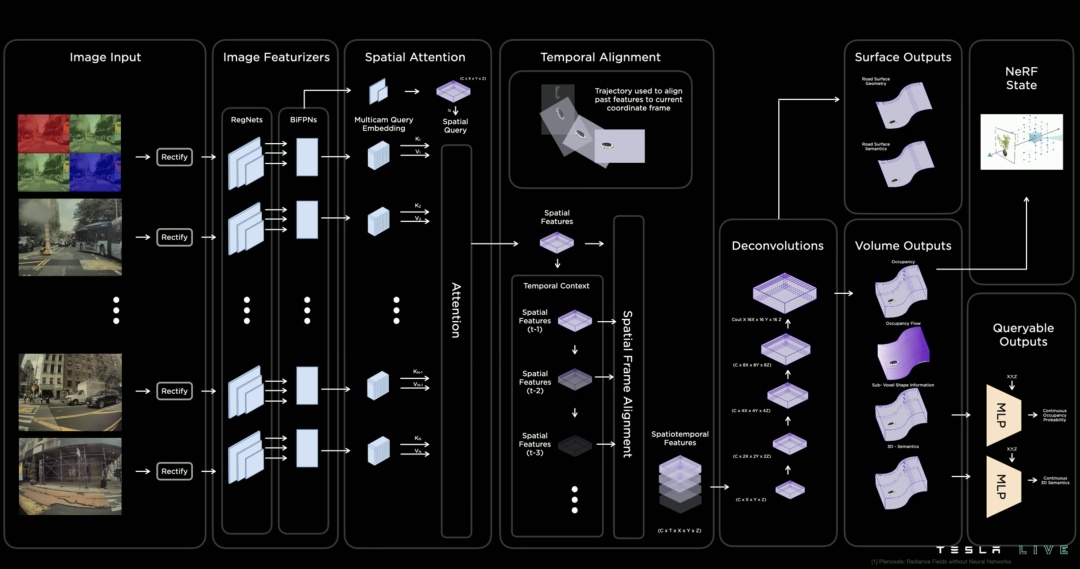
作为一名工程师,你不得不承认,特斯拉的解决方案是「优雅」的。他们最早意识到:
只要依然依赖「后处理规则」,自动驾驶就永远只能是 L2。
以前的感知是「盲人摸象」,摄像头看摄像头的,雷达看雷达的,最后再强行凑在一起。这就导致了著名的「幽灵刹车」——雷达觉得前方有障碍,摄像头觉得那是影子上的一团黑,到底信谁?这也是网上很多非从业者在「纯视觉 vs 激光雷达」路线争论中最喜欢用的例子。
新一代的技术(BEV + Transformer)开始尝试在特征层面融合。我们不再告诉车“这是路沿,那是车道线”,而是把所有传感器的数据扔进一个巨大的神经网络,让 AI 自己去构建一个 3D 的向量空间。
这不仅是算法的胜利,更是数据闭环的胜利。
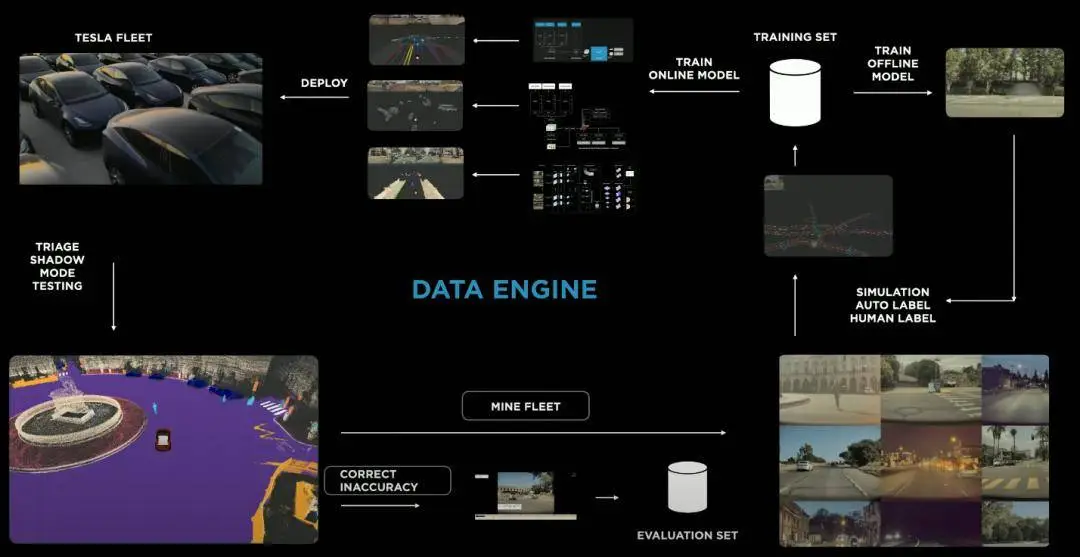
为什么这么说?因为当大家开始抄作业的时候才发现,原来时间同步和标定的精度得这么高,数据量得那么大。以前采集的很多数据完全是无价值的,但重新采集和标注又需要大量时间和金钱。
于是,第一波洗牌开始了。
在这个阶段,大家也开始意识到,自动驾驶的核心壁垒,不再是你的逻辑写得有多好,而是你有多少高质量的、被清洗过的**「完美数据」**。
在这之后,大家的差距开始急速拉开。一旦走通数据闭环的公司,就可以持续积累高质量数据,并验证新方法,智驾能力日新月异;反之,有的公司始终无法迈过数据这个坎。我相信即便是现在,依然有很多小公司使用的不是 BEV 架构的方法。
03. 端到端:是终极答案,还是 AGI 的幻影?
时间来到现在,每个人都在谈论「端到端」(End-to-End)。
所谓的端到端,简单说就是:
视频输入 → 神经网络 → 控制指令输出
Tesla 甚至使用的是更加 Native 的 Raw 格式相机数据作为输入(当然这需要海量数据支撑)。
中间那些感知、规划的模块边界被打破了。公司的组织架构在调整,学生的学习路线在改变,很多岗位(例如传统规控算法、SLAM 建图等)正在消失。
此时的车子不再是通过规则在思考,而是像人一样,通过「直觉」在驾驶。
这听起来很美,对吧?毕竟这很优雅,而且上限也很高,只要跨过数据和算力的大山,似乎就可以解决最终难题。
但作为一线从业者,我必须泼一盆冷水:
端到端,比我们预想的要难得多。
当我们试图训练一个端到端模型时,我们实际上是在逼迫 AI 去理解物理世界的运行规律,去预测行人的意图,去博弈。为了不断突破边界,于是也出现了很多例如 E2E+VLM、VLA、World Model 等技术路线。
每一种路都有自己合理的解释,但是那样真的是正确的方向吗?我不知道。
但我知道的是:
这哪里是在做自动驾驶?如果真的能达成我们想要的那个目标,这分明是在做 AGI(通用人工智能)。
我们想要的是一个和人一样的驾驶员,仅此而已!
如果六年前有人告诉我:
「想要实现完全自动驾驶,你必须先造出一个接近人类水平的 AI」
我一定会觉得那是天方夜谭,趁早转行去卖煎饼果子了。
但站在今天看,这似乎是唯一的路。
我们以为我们要造的是一个马车夫,结果发现必须先造一个「人」。这也是为什么现在的自动驾驶看起来依然不够完美——因为 AGI 的黎明还没真正到来。
当然,或许从一开始,有的大牛就已经想到过这个实现路径。只是因为现在 AI 的发展让我们见到了 AGI 的曙光,所以才敢这么做。
04. 写在最后
最后,我想畅想一下未来,想一想未来自己应该朝着什么方向去做,哪些东西是不变的、需要持续不断积累的。
首先得先回答一个问题:现在的自动驾驶技术解决问题了吗?短期内会被解决吗?
我个人觉得短期内是不会被解决的。不是技术的问题,而是期望的问题。
这让我想起十几年前高中时候的智能手机。那时候 iPhone 4S 在当时看来已经完美无缺,我无法想象未来手机还需要再做什么创新。但用今天的眼光看,它除了经典,似乎没有任何地方可以与现在的手机比拟。
人的需求是随着技术进步而水涨船高的。
当自动驾驶只会跑直线时,我们希望它能转弯;当它能转弯时,我们希望它能像老司机一样博弈加塞;当它真的像老司机一样时,我们可能又会要求它能陪聊、能懂我的心情。
所以我觉得智驾技术是一场短期内看不到尽头的长跑。但正因为看不到尽头,才更加迷人。这也让我们这些从业者对未来有憧憬,不应该过度担心行业没落,而是依然要积极拥抱新技术、新变化。
那相较于其他传统行业可以依靠工作经验「吃资历」,我们在这个日新月异的行业里,似乎没有什么可以积累的?
我们可以做些什么呢?
首先我觉得高风险、高竞争带来的是高收益,我们这个行业的人均薪资应该是领先同龄人的。所以首先应该端平心态,不能想着「既要又要」,不然整天焦虑会很痛苦。
其次,我们得在其中找「不变」的、可以积累的东西。接下来我可能会说一些人会反感、或者觉得是废话的观点:
观点 1:锻炼和培养自己学习和解决问题的能力
有的人可能会觉得这是废话,但我问你:如果要跟上技术进步、与应届生竞争,是不是必须得学新东西?既然学习新技术躲不掉,那效率和方法就是至关重要的。
你的身边是不是有那种学习能力很强、对什么接收都很快、行动也很快的人?如果有,那种人就是你要学习的对象。同样的,身边是不是也有那种没有冲劲、沟通费劲的同事,或者做事看起来比较“笨拙”的新人?这就是学习能力和解决问题能力的差异。有了这个,我相信在任何领域被淘汰的概率都很小。
观点 2:人脉!
我们搞技术的就是喜欢钻在技术问题里,不喜欢团建、聚会、讲座等等,似乎这些都是其他传统行业喜欢搞的。技术行业嘛,技术为王。
但是,人脉真的是一个可以靠时间而积累的东西。人生在世这么些年,总会有些时刻是可以帮助别人,也有需要别人帮助的时刻。而这些就是建立联系和信任的基石。如果多参与一些技术群里的讨论,这样的积累就会多一分。你不知道哪一天,自己或许就会需要这份人情。
最后,我再说明一下。
在这个系列里,我不想说些大家都知道的「正确的废话」。我会尽量从工程师视角,说些自己的想法。
当然,也很喜欢与大家建立一些联系,探讨一些大家共同感兴趣的话题,可以深入地聊一下。
接下来,我打算用几篇文章来从比较基础的几个角度,谈谈我对自动驾驶的认知,大概会包括传感器、技术框架、方案落地、数据闭环等角度。
感兴趣的朋友可以关注一下!
(完)
【优化版本 v1 · 待你审阅】
📝 按你的写作风格调整了开头摘要、引号、节奏与几处 AI 味表达。原文保留在上方,定稿时告诉我「可以定了」我再覆盖。
入行六年,从模块拼装一路走到端到端,自动驾驶这门技术变得越来越像在造 AGI——可我们想要的,明明只是一个会开车的人。
写在前面
前不久收到一封邮件。发件人是位毕业三四年的同学,他说当年我学生时代写的几篇博客和开源的小工程,帮他顺利做完了毕设。
那一刻挺触动的。原来那些稚嫩的输出,真有人看,也真的帮到了人。
工作六年,我中断写作很久了。偶尔开源点东西,从没系统聊过自己在做什么。这封邮件让我想,也许可以重新开始写。
简单交代一下背景:毕业就入行,六年都在做感知,几段经历都在小厂,目前在一家初创公司带感知算法组。视角有限,观点不一定对,但只要对你有一点点用,就值了。
这个系列我不会推公式、不会贴代码,就从工程师的视角聊一些宏观的事。我写得轻松,你也看得轻松。
一、那个相信「拼图」的年代
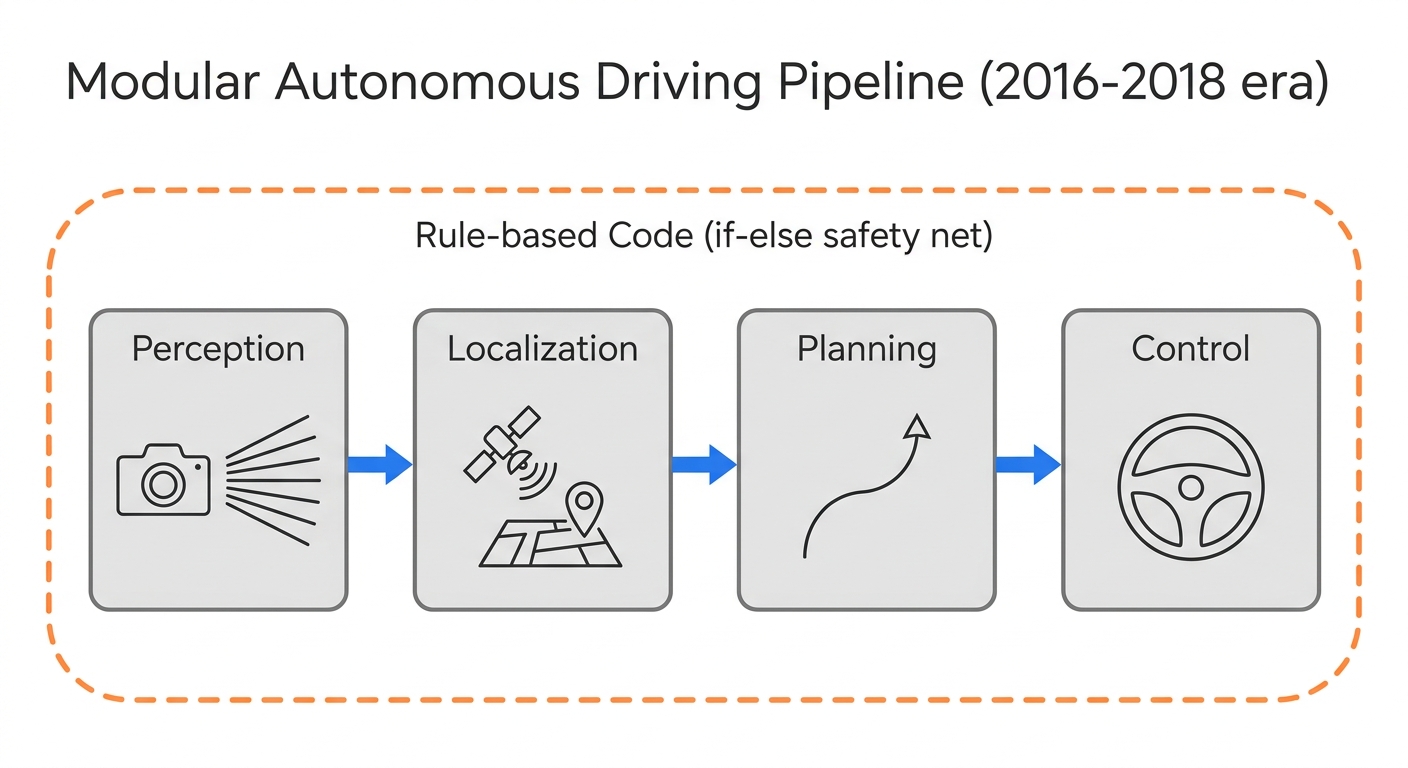
2016 到 2018 年前后,问怎么实现自动驾驶,答案出奇地一致:Divide and Conquer,分而治之。
把「开车」这件难事拆碎:
- 感知组做眼睛,认出前面是人是车
- 定位组算清楚自己在哪,要厘米级
- 规划组拿着感知和地图,算一条不撞、合法、还得舒适的轨迹
- 控制组把轨迹翻译成油门和方向盘
现在回头看,这像个东拼西凑的「弗兰肯斯坦」。但在当时,这就是最优解。
为什么?那时候的 AI 像个刚认字的小朋友,没人敢把方向盘真的交给它。我们只能在外面套一层规则代码当保姆。
我记得为了处理「路口左转遇到对向遮挡」这一个场景,规划组同事写了几百行 if-else:
「如果前车速度小于 x,且距离大于 y,且左侧无障碍物,则……」
封闭园区和高速上,这套思路够用,也让最早一批 Demo 公司老板赚了不少钱。
但车一进城,噩梦就开始了。人类的世界,不是 if-else 能穷举的。我们试图用有限的规则去定义无限的世界——这本身就是一种傲慢。
二、特斯拉的「优雅」与规则的崩塌
转折大概在特斯拉疯狂迭代 Autopilot、AI Day 上抛出 BEV 的那段时间。很怀念那场科技盛宴,也不知道 Tesla 哪天会重启。
作为工程师,你不得不承认那套方案是「优雅」的。他们最早意识到一件事:只要还在依赖后处理规则,自动驾驶就永远停在 L2。
以前的感知是盲人摸象。摄像头看摄像头的,雷达看雷达的,最后强行凑到一起。「幽灵刹车」就是这么来的——雷达说前面有障碍,摄像头说那是影子上的一团黑,到底信谁?这也是「纯视觉 vs 激光雷达」路线之争里被说烂了的例子。
新一代方案(BEV + Transformer)开始在特征层做融合。我们不再告诉车「这是路沿,那是车道线」,而是把所有传感器的数据扔进一个网络,让它自己构建 3D 向量空间。
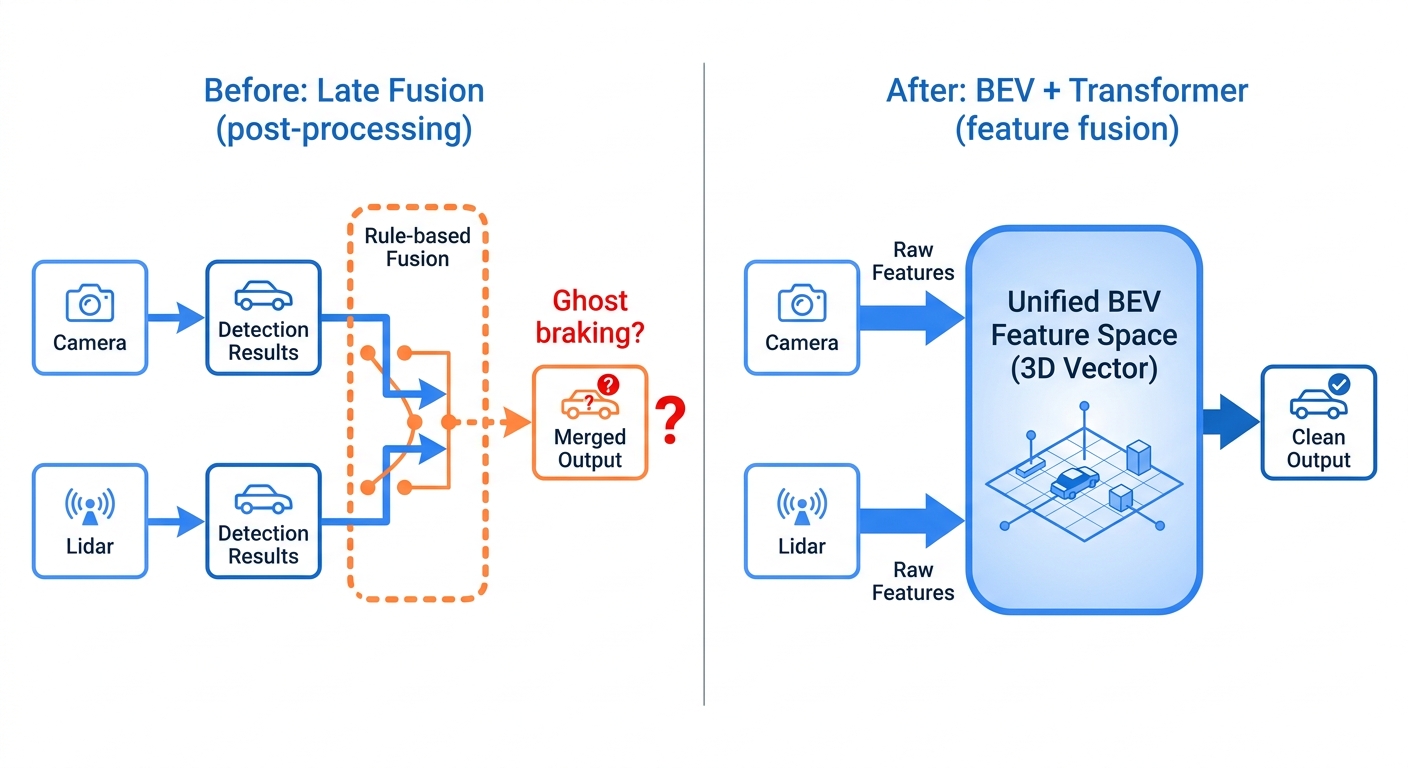
这是算法的胜利,更是数据闭环的胜利。
为什么?大家一上手抄作业才发现,时间同步得这么准、标定得这么严、数据量得这么大。以前采的数据大量是无用功,重新采、重新标,又烧时间又烧钱。
第一波洗牌就这么开始了。
那段时间大家才慢慢明白:自动驾驶的核心壁垒,不再是逻辑写得多漂亮,而是你手里有多少被清洗过的高质量数据。
差距从这里开始急速拉开。走通数据闭环的公司一日千里,走不通的,在数据这道坎前一直绊倒。我相信即便到现在,依然有不少小公司压根没用上 BEV。
📚 展开阅读:BEV 流派两条主线可以对照看 Untitled(Transformer 路线)与 Untitled / Untitled(LSS + 显式深度路线);多模态特征层融合直接看 Untitled。我之前还写过一篇 BEV 系列经典论文解读:流派对比、局限性与新展望。
三、端到端:终极答案,还是 AGI 的幻影?
现在每个人都在聊端到端。简单说就是:
视频输入 → 神经网络 → 控制指令输出
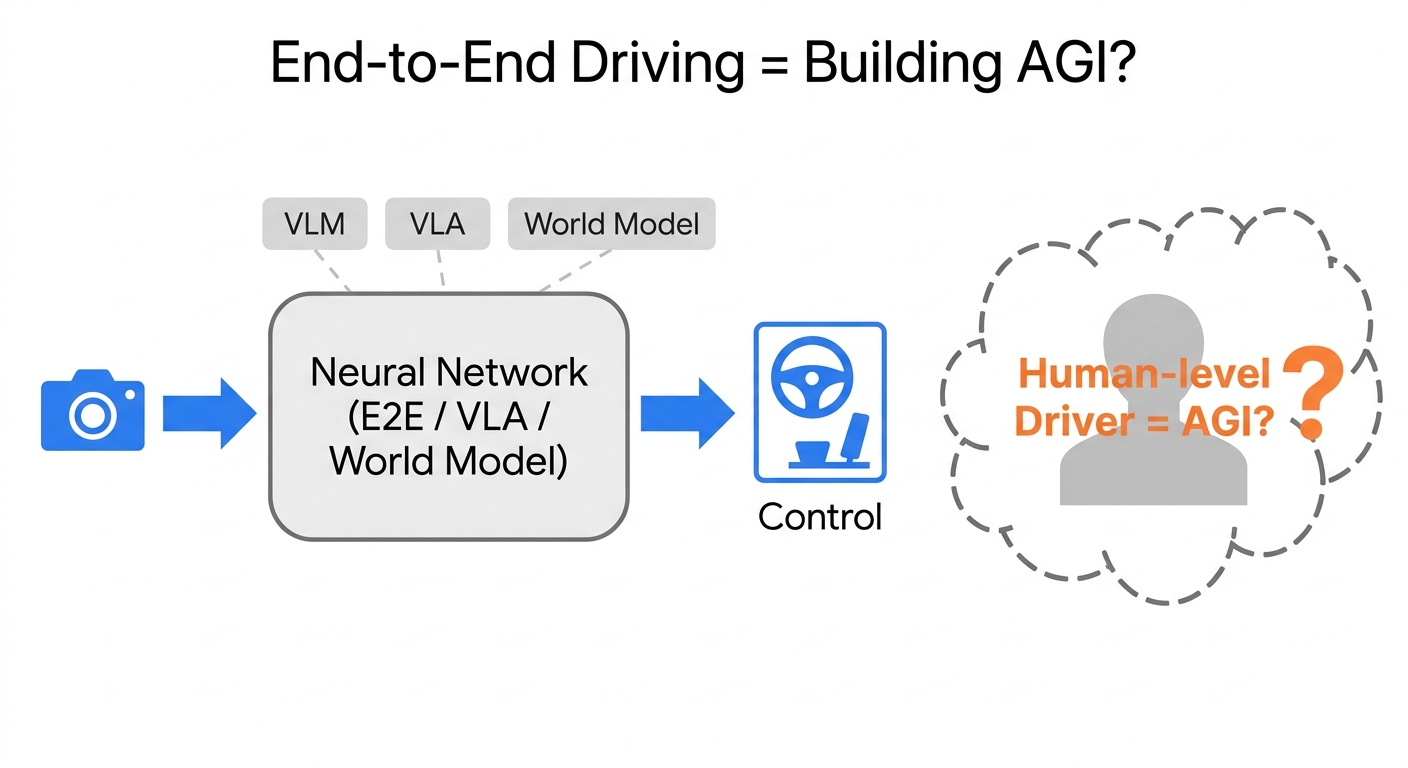
特斯拉甚至直接用更原生的 Raw 相机数据(当然背后是海量数据撑着的)。中间那些感知、规划的模块边界全部打破。公司在调架构,学生在改学习路径,传统规控、SLAM 建图这类岗位正在快速消失。
车不再用规则思考,而是像人一样靠「直觉」开车。
听起来很美对吧?方案优雅,上限又高。只要跨过数据和算力的山,似乎就能解决终极问题。
但我得泼盆冷水:端到端,比我们想象的难得多。
训练一个端到端模型,本质上是在逼 AI 去理解物理世界、预测行人意图、跟别人博弈。为了不断突破上限,又冒出 E2E+VLM、VLA、World Model 一堆路线。
每条路都讲得通,但哪条是对的?没人知道,我也不知道。
我只知道一件事:这哪里是在做自动驾驶?这分明是在做 AGI。可我们想要的只是一个像人一样的司机,仅此而已。
如果六年前有人告诉我,「想搞定完全自动驾驶,你得先造出一个接近人类水平的 AI」,我大概率会觉得是天方夜谭,转行去卖煎饼果子。
但站在今天看,这似乎是唯一的路。我们以为要造的是马车夫,结果发现得先造一个「人」。今天的智驾还远远不够好,正是因为 AGI 的黎明还没真正到来。
或许早就有大牛预见了这条路径,只是 AI 这两年的爆发,才让大家敢真的这么干。
📚 展开阅读:端到端的几条主流分支——经典代表 Untitled;感知 + 预测 + 规划一体化的 Untitled;用 Diffusion + RL 走端到端的 Untitled;把 Occupancy 和 VLA 缝在一起的 Untitled。
四、写在最后
聊完技术,回到自己。过完年我就 30 了,最近也在理职业生涯下一步该怎么走。
先回答一个问题:当下的自动驾驶,问题解决了吗?短期会被解决吗?
我的判断是不会。不是技术不行,是期望追得太快。
想想十几年前的 iPhone 4S。当时用着觉得完美无缺,根本想不出未来还能怎么创新。但今天再看,它除了情怀,没一项能跟现在的手机比。
人的需求总是随技术水涨船高的。
车只能跑直线时,我们盼着它会转弯;它会转弯了,盼着它能像老司机那样博弈加塞;真到了老司机水平,可能又希望它能陪聊、读得懂我的情绪。
智驾是一场短期内看不到尽头的长跑。但也正因为看不到尽头,它才迷人。
那么问题来了——其他行业可以靠工龄「吃资历」,我们这种日新月异的活儿,还能积累什么?
我想说两点,可能有人觉得是废话,但我自己确实信。
一、把学习和解决问题的能力练扎实。
跟上技术更新、跟应届生竞争,意味着你必须不停学新东西。既然躲不掉,方法和效率就是命。
身边总有那种学什么都快、行动也快的人;也总有那种没冲劲、沟通费劲、做事笨拙的人。差距不在智商,在学习和解决问题的肌肉。这块练好了,去任何行业都不容易被淘汰。
二、人脉。
搞技术的容易钻在问题里,反感团建、聚会、讲座,觉得那是传统行业的事。技术行业嘛,技术为王。
但人脉是真的能靠时间复利的东西。人活这些年,总会有能帮别人和需要别人帮的时刻。多在技术群里聊几句、多参加点活动,这些联系迟早会派上用场。
接下来这个系列,我打算从基础开始聊:传感器、技术框架、方案落地、数据闭环。不讲正确的废话,只说自己一线踩出来的看法。
感兴趣就关注一下,有想聊的话题也欢迎来找我。
(完)