
前言
我在前面多篇文章已经讨论过,智驾的发展是从模块化逐步走向端到端的过程。端到端是现在能看到的未来趋势,而AGI很有可能是最终的发展方向。
具身智能在最近两年才逐步进入大众视野。它的起步技术路线就是端到端方向的VLA,起点相对较高。这得益于当前大模型技术的发展,让具身智能有了实现的可能性。
由于具身智能的任务难度更高,再加上智驾领域积累的经验(很多创业者本身就来自智驾领域),业内一开始就明确必须走端到端路线。同时,由于数据稀缺,物理AI和sim2real成为这个领域的热门技术。而这些技术同样适用于智驾领域。正如许多人所说:智驾本质上也是具身智能的一种,而且是相对简单的形态。
因此,随着业内对技术路径认识的统一,智驾与具身智能很可能会采用同源技术,并形成互相促进的关系。对于从业者而言,在学习和选择技术时也需要有清晰的认知。不必过于悲观地认为智驾收缩了就要赶紧转向具身智能占坑,因为这两个方向终将殊途同归。
技术同源的深层证据
当我们深入对比最前沿的智驾方案与具身智能方案时,会发现它们在底层技术上已经高度趋同。这种趋同不是偶然,而是两个领域在解决同一类问题时的必然选择。
NVIDIA Alpamayo:智驾的VLA化

NVIDIA在2026年CES上发布的Alpamayo系列模型,标志着智驾正式进入VLA时代。Alpamayo 1是业界首个专为自动驾驶设计的思维链推理VLA模型,采用100亿参数架构。
架构设计:Alpamayo采用了与具身智能VLA完全相同的架构范式——视觉编码器+语言模型+动作解码器。视觉输入通过编码器转换为token,送入语言模型进行推理,最后输出驾驶轨迹。这与OpenVLA等具身智能模型的pipeline完全一致。
推理能力:Alpamayo的核心创新是引入了Chain-of-Thought推理,模型会先用自然语言描述场景、分析关键物体的影响、推导驾驶决策,最后生成具体轨迹。这种「先思考再行动」的模式,正是具身智能VLA的标准做法
开源策略:NVIDIA将Alpamayo的模型权重、推理脚本全部开源,并提供了仿真框架和数据集。这与OpenVLA的开源路线完全一致,都在构建一个开放的生态系统。
Tesla FSD V14:端到端的终极形态
Tesla FSD V14代表了端到端自动驾驶的最新进化。根据特斯拉自动驾驶副总裁Ashok Elluswamy在ICCV 2025的演讲,V14实现了几个关键突破:
模型规模:V14的神经网络参数量是上一代的10倍,这个扩展规律与大语言模型的scaling law完全一致。更重要的是,特斯拉引入了类似大语言模型的底层框架性变革。
多模态融合:V14不仅处理视觉输入,还引入了音频数据。系统采用SDF(Signed Distance Field)占用网络技术,实现了从「几何框」到「物理世界」的精细理解。这种多模态处理方式,正是VLA模型的核心特征。
世界模拟器:特斯拉发布的世界模拟器可以生成照片级逼真的驾驶场景,用于闭环评估和强化学习训练。这与具身智能领域的sim2real技术完全同源——都是用仿真环境解决真实数据稀缺的问题。
OpenVLA:具身智能的代表性方案
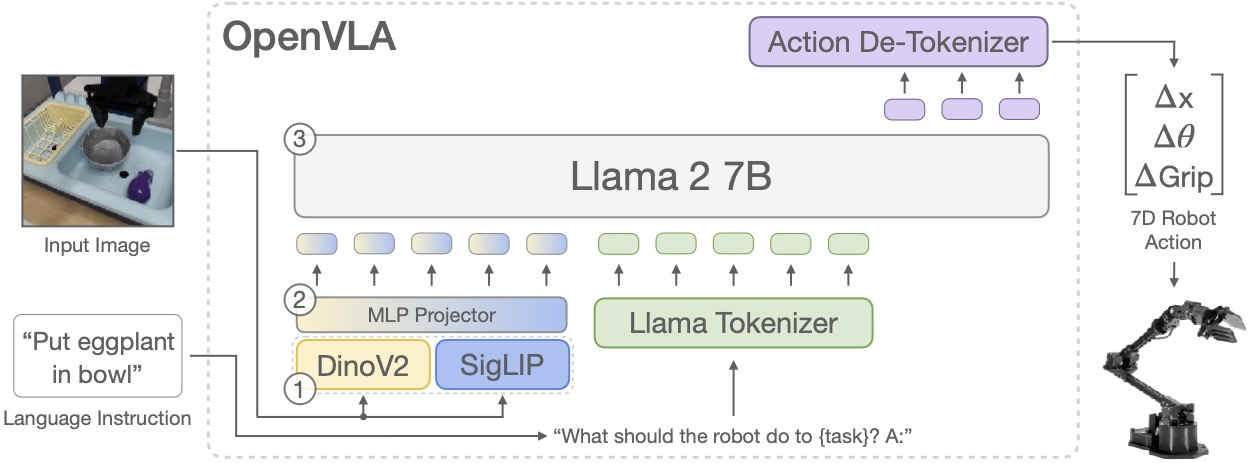
OpenVLA是斯坦福大学2024年推出的7B参数开源VLA模型,成为具身智能领域的重要基准。让我们看看它与智驾方案的技术对比:
模型架构:OpenVLA基于Llama 2语言模型,结合SigLIP和DINOv2双视觉编码器。这个架构与理想MindVLA、NVIDIA Alpamayo高度相似——都是「视觉编码器+大语言模型+动作头」的三段式结构。
训练数据:OpenVLA在970k真实机器人演示数据上训练,数据来自Open X-Embodiment数据集。这个数据规模看似不大,但通过跨机器人、跨任务的数据混合,实现了强大的泛化能力。智驾领域的做法完全相同——理想汽车用12亿公里数据训练VLA,特斯拉每天收集相当于500年的驾驶数据。
动作表示:OpenVLA支持7自由度连续控制,采用回归方式直接预测动作值。Alpamayo同样采用连续动作表示和L1回归目标。两者都放弃了早期的离散化token方案,因为这会损失精度。
算法层面:殊途同归的选择
端到端架构的统一:无论是Tesla的纯视觉端到端,还是NVIDIA Alpamayo的VLA,再到OpenVLA的机器人控制,都选择了端到端架构。这个选择的底层逻辑是:通过神经网络打通感知-推理-动作的全链路,避免模块化方案的信息损耗。
大模型能力的借用:智驾和具身智能都在积极利用预训练大模型的能力。Alpamayo、理想MindVLA使用语言模型做推理,OpenVLA同样基于Llama 2。这种做法的价值在于,语言模型在互联网数据上学到的常识推理能力,可以迁移到物理世界的决策中。
推理链的引入:从Tesla V14的「近乎智能生物般的感知能力」,到Alpamayo的Chain-of-Thought,再到OpenVLA的语言推理,都在试图让模型具备「解释为什么这样做」的能力。这不仅提升了性能,更重要的是增强了可解释性和可信度。
数据层面:同样的瓶颈与突破
真实数据的局限:智驾和具身智能都面临同样的问题——人类演示数据分布有限。人类驾驶数据多为白天、晴天、无事故场景;机器人演示数据难以覆盖所有物体和任务组合。这个瓶颈在两个领域推动了相同的解决方案。
仿真的关键作用:特斯拉的世界模拟器、NVIDIA的Cosmos平台、具身智能的sim2real技术,本质上是同一件事——用仿真生成稀缺场景的数据。Cosmos平台同时服务于自动驾驶和机器人两个领域,这不是巧合,而是因为底层需求完全一致
合成数据的生成:两个领域都在探索用生成式模型创造训练数据。特斯拉用扩散模型生成驾驶场景,具身智能用物理仿真生成机器人轨迹。这些合成数据不仅用于训练,更用于强化学习中的策略优化。
数据闭环的效率:理想汽车强调的「影子模式+云端训练+车端部署」数据闭环,与具身智能的「真实采集+仿真扩展+策略迭代」完全同构。两者都在追求更快的迭代速度,谁的数据飞轮转得快,谁就能更快提升模型能力。
训练层面:相同的范式转变
从模仿学习到强化学习:智驾最初依赖模仿学习——让模型学习人类司机的行为。但理想汽车发现,简单堆数据已经遇到瓶颈,从1000万Clips开始性能提升放缓。解决方案是引入强化学习,在仿真中让模型自己探索。具身智能同样经历了这个转变,早期的BC(Behavior Cloning)方法已经让位给RL+模仿学习的混合方案。
自我博弈与对抗训练:特斯拉在仿真器中使用强化学习进行策略优化,让不同策略相互竞争。这与OpenAI在机器人领域使用的自我博弈技术完全一致。通过在仿真中试错数百万次,模型能够学到比人类演示更优的策略。
多任务学习:OpenVLA在970k演示数据上训练,覆盖29个任务和多个机器人。Alpamayo在Open X-Embodiment数据集上训练,同样覆盖多种场景。这种多任务混合训练的价值在于,模型能够学到任务间的共性,从而获得更强的泛化能力。智驾领域的逻辑完全相同——理想用多城市、多天气、多场景的混合数据训练VLA。
仿真层面:共享的基础设施

物理引擎的统一:NVIDIA的Newton物理引擎同时支持自动驾驶和机器人仿真。这不是技术复用,而是因为两个领域需要相同的物理建模能力——重力、摩擦、碰撞、材质属性。特斯拉世界模拟器中的物理动态,与具身智能sim2real中的物理仿真,遵循相同的原理。
实时推理的要求:NVIDIA强调Newton的响应时间低于0.01秒,这对于高频控制至关重要。智驾需要10-30Hz的决策频率,双臂机器人需要更高频率。但技术挑战完全相同——如何在有限算力下实现低延迟、高精度的仿真。
sim2real的挑战:从仿真到真实世界的迁移gap,是两个领域共同的难题。解决方案也高度一致——域随机化、域适应、真实数据微调。特斯拉用真实传感器数据微调仿真模型,具身智能用真实机器人数据做sim2real迁移,方法论完全相通。
算力层面:相同的基础设施需求
训练算力的规模:理想汽车的13 EFLOPS云端算力、特斯拉的Dojo超算、地平线的A800集群,与具身智能训练所需的算力规模处于同一量级。NVIDIA的Rubin平台同时服务两个领域,因为底层需求完全一致——大规模模型训练、海量数据处理、高频仿真迭代。
推理算力的平衡:车端算力受限于成本和功耗,理想用两颗ORIN X分别跑快慢系统,总算力约508 TOPS。机器人端侧算力同样受限,OpenVLA探索量化、剪枝等压缩技术。两者都在追求「性能与效率的最佳平衡点」,都需要模型压缩、混合精度推理等工程优化。
边缘-云协同:智驾的「车端推理+云端训练」架构,与具身智能的「机器人端推理+云端策略更新」完全同构。边缘设备负责实时决策,云端负责模型迭代。这种架构不是巧合,而是在算力、延迟、成本三者之间的最优解。
评估层面:趋同的指标体系
成功率指标:智驾用MPI(平均接管里程)衡量性能,OpenVLA用任务成功率评估。表面上看指标不同,但本质都在衡量「在多少次尝试中,模型能够正确完成任务」。理想MindVLA在LIBERO基准上达到97.1%成功率,OpenVLA在同一基准上的表现类似,说明评估标准已经趋同。
泛化能力测试:两个领域都强调zero-shot泛化——在未见过的场景中表现如何。Tesla V14强调对新物体、新场景的适应能力,OpenVLA同样测试跨机器人、跨任务的泛化。评估方法高度一致——构建分布外测试集,衡量模型在新场景中的表现。
长序列鲁棒性:智驾需要处理长时序决策,一次驾驶可能持续数小时。具身智能的长序列任务同样需要模型保持稳定。两者都在探索记忆机制、上下文管理等技术,解决长序列中的遗忘和漂移问题。
趋同的必然性
智驾端到端与具身智能VLA的技术趋同,不是偶然的模仿,而是源于三个深层原因:
问题本质的相同:两者都是「感知-推理-动作」的闭环控制问题。输入是传感器数据,输出是物理动作,中间需要理解环境、预测未来、规划策略。这个问题结构决定了解决方案会趋同。
技术路径的收敛:当端到端遇到瓶颈时,引入大模型的语言推理能力是自然选择。当VLA需要处理复杂场景时,端到端的全局优化是必然方向。两条路径从不同起点出发,但都在向「端到端+大模型+强化学习」的方向收敛。
基础设施的共享:NVIDIA提供统一的算力平台、仿真引擎、开源模型。当两个领域使用相同的基础设施时,技术栈自然会趋同。Alpamayo既是自动驾驶模型,也是VLA模型,这种身份的模糊本身就说明了边界的消失。
从业者需要认识到,智驾与具身智能正在成为同一技术树的两个分支。在端到端、大模型、物理仿真、强化学习这些核心技术上的积累,可以在两个领域之间无缝迁移。今天训练智驾模型的工程师,明天可以用同样的技能训练机器人策略。这不是技能的泛化,而是技术栈的统一。
技术统一后的三个启示
当智驾与具身智能在底层技术上走向统一,这个趋势会带来三个层面的深远影响。
从业者的技能迁移路径
技术栈的统一意味着从业者的核心竞争力发生了变化。过去在智驾领域积累的感知算法经验、在具身智能领域掌握的VLA训练方法,现在都成为可迁移的通用技能。
端到端架构的设计能力成为核心。无论是设计视觉编码器、优化语言模型推理、还是调试动作解码器,这些能力在两个领域都适用。理想汽车的MindVLA团队可以无缝转向机器人控制,斯坦福OpenVLA的研究者同样能够参与自动驾驶项目。
数据闭环的工程能力变得更有价值。会搭建影子模式的工程师,也会搭建机器人的云端训练系统。懂得如何用仿真数据扩充真实数据的团队,在智驾和具身智能领域都是稀缺资源。
物理世界建模的理解深度成为分水岭。能够理解Newton物理引擎、掌握sim2real技术、处理多模态融合的人才,不再局限于某个垂直领域,而是成为物理AI时代的通用型专家。
对于正在考虑职业方向的从业者,不必纠结「智驾还是具身智能」这个伪命题。真正需要关注的是,自己是否在端到端、大模型、强化学习、物理仿真这些核心技术上有足够的深度。当技术栈统一后,领域边界会自然消失。
产业的跨界创新机会
技术统一打开了跨领域创新的可能性。最直接的机会来自技术迁移。
NVIDIA的Alpamayo和Cosmos平台已经展示了这种可能——同一套模型可以同时服务自动驾驶和机器人。未来会出现更多这样的「双栖」方案:在智驾场景中验证的端到端架构,可以快速移植到仓储机器人;在机器人领域训练的VLA模型,可以反向优化智驾的决策层。
数据层面的协同会加速。智驾公司积累的海量真实世界数据,可以用于训练通用的物理世界模型。具身智能公司在仿真环境中探索的技术,可以帮助智驾应对长尾场景。Open X-Embodiment这样的跨领域数据集,价值会持续提升。
投资机会也在重新定义。过去「押注智驾还是押注机器人」的选择题,现在变成了「谁在底层技术上有更深的积累」。拥有端到端全栈能力、掌握大规模数据闭环、能够快速迁移技术到不同场景的团队,会获得更高的估值溢价。
供应链层面会出现整合。芯片厂商不再需要为智驾和机器人设计完全不同的产品线,NVIDIA的ORIN和Rubin就是证明。算法公司可以同时服务两个领域,降低研发成本、提高技术复用率。
下一阶段的技术突破点
当智驾与具身智能在现有技术上趋同后,下一阶段的突破会发生在哪里?
通用世界模型是最重要的方向。特斯拉的世界模拟器、NVIDIA的Cosmos、具身智能的物理仿真,现在还是各自为战。但它们的目标是一致的——构建一个理解物理规律、能够预测未来状态的通用模型。谁先做出这个通用世界模型,谁就掌握了物理AI时代的操作系统。
从感知到认知的跨越是关键瓶颈。现在的端到端模型本质上还是模式匹配——在训练数据中学到「看到红灯就刹车」的映射关系。但真正的智能需要理解「为什么红灯要刹车」「什么情况下可以违反规则」。这需要将常识推理、因果理解引入物理世界的决策中。Alpamayo的Chain-of-Thought只是开始,更深层的认知能力还在探索中。
强化学习的大规模应用会成为分水岭。模仿学习已经接近瓶颈,理想汽车的数据显示,从1000万Clips开始性能提升就明显放缓。强化学习让模型在仿真中自己探索,理论上可以超越人类演示的上限。但如何让强化学习在物理世界中稳定、安全、高效地工作,还没有成熟方案。特斯拉在世界模拟器中使用RL是一个方向,但距离大规模落地还有距离。
多模态融合的深度会持续提升。Tesla V14引入音频数据,未来可能还会引入更多模态——触觉、力反馈、温度。每增加一个模态,模型对物理世界的理解就更深一层。但如何在有限算力下处理多模态数据、如何让不同模态之间有效协同,这些工程问题需要突破。
端侧推理的效率优化决定了技术能否规模化落地。理想的22亿参数VLM需要两颗ORIN X,这个成本对于量产车来说还能接受,但对于消费级机器人就太贵了。模型压缩、量化、剪枝、知识蒸馏,这些技术会持续演进。NVIDIA的Rubin平台将推理成本降低到上一代的十分之一,这种硬件进步会推动算法创新。
智驾与具身智能的技术统一,不是终点,而是新起点。当两个领域不再各自为战,而是共享技术栈、共享数据、共享基础设施,整个物理AI的发展速度会加快。下一个五年,我们可能会看到通用世界模型的出现、看到强化学习在真实世界的大规模应用、看到从感知到认知的真正跨越。
而这一切的前提,是认识到智驾与具身智能本质上是同一个问题——如何让AI理解并操控物理世界。技术的统一已经开始,接下来的竞争,是在统一的技术栈上谁能走得更深、更快。
(完)